You give a large language model a clear instruction at the start of a long document — "Respond only in JSON" or "Never reveal the customer's account number" — and 20,000 tokens later, it quietly ignores you. The rules you set up front seem to evaporate. This is context decay, and it is one of the most frustrating, least understood failure modes in modern AI.
Context decay is the tendency of an LLM to "forget" or down-weight instructions placed far from the point where it generates its answer — typically at the very beginning of a long prompt or chat history. As the surrounding context grows, those early directions lose their grip on the model's behavior.
In this guide, you'll learn what context decay actually is, the mechanics behind why it happens, how it differs from related issues like context rot and the lost-in-the-middle problem, and seven practical strategies to keep your instructions sticking from the first token to the last.
What Is Context Decay?
Context decay describes the measurable drop in how reliably an LLM follows information as that information moves further from the model's current generation point. The instruction isn't deleted — it's still inside the context window — but its influence on the output fades.
The classic symptom looks like this: you paste a long article after the instruction "Summarize the following in three bullet points," and the model returns six paragraphs. By the time it finished reading 50,000 tokens of text, the three-bullet rule had decayed into background noise.
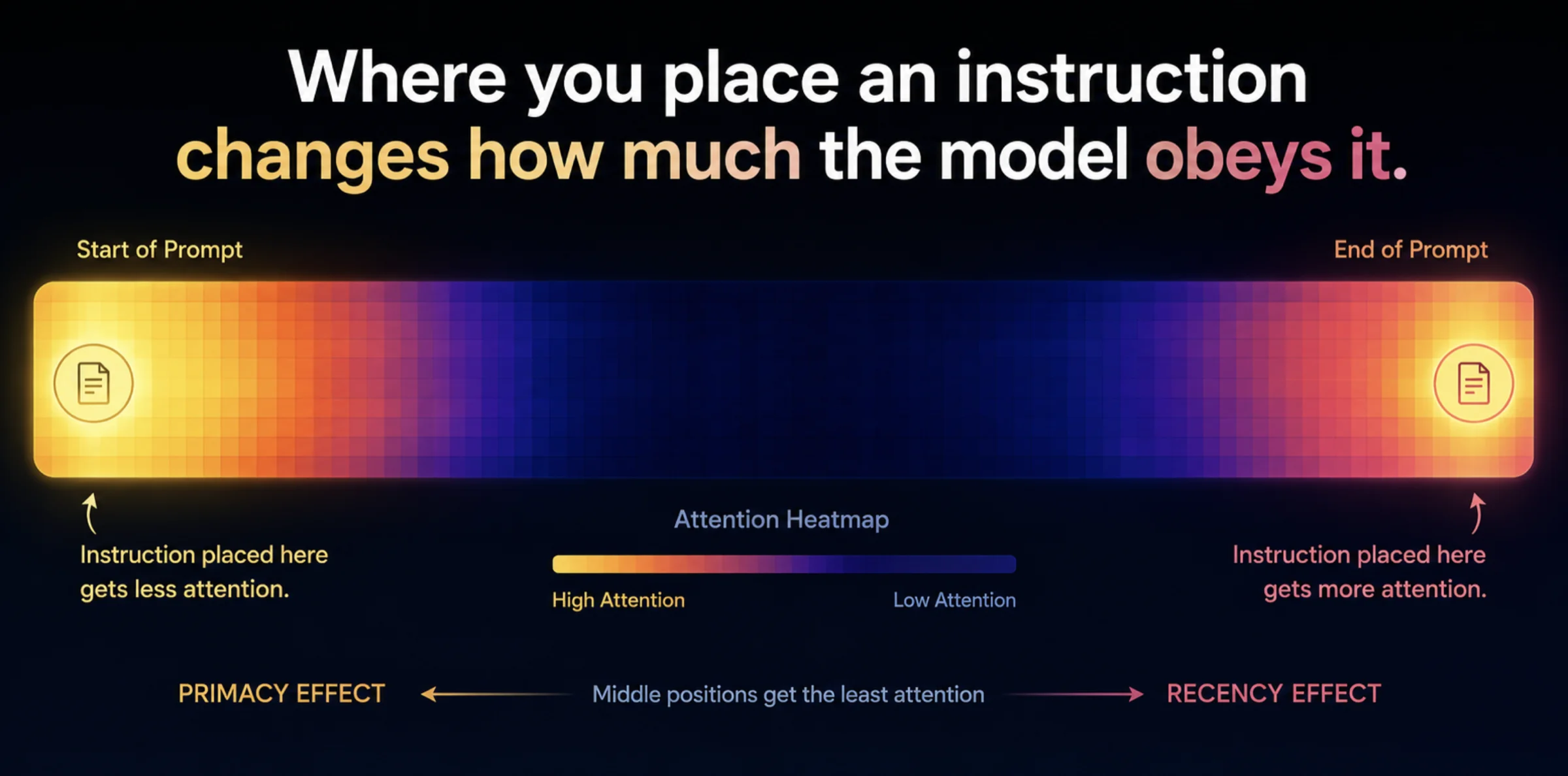
Context decay matters because it breaks the core assumption most people have about prompts: that anything you write will be "remembered" equally. It won't. Position is power. Where you place an instruction changes how much weight the model gives it.
Key takeaway: In a long context, what you say matters less than most people think, and where you say it matters far more.
This is closely related to a broader concept of context engineering, where structure and ordering often beat clever wording.
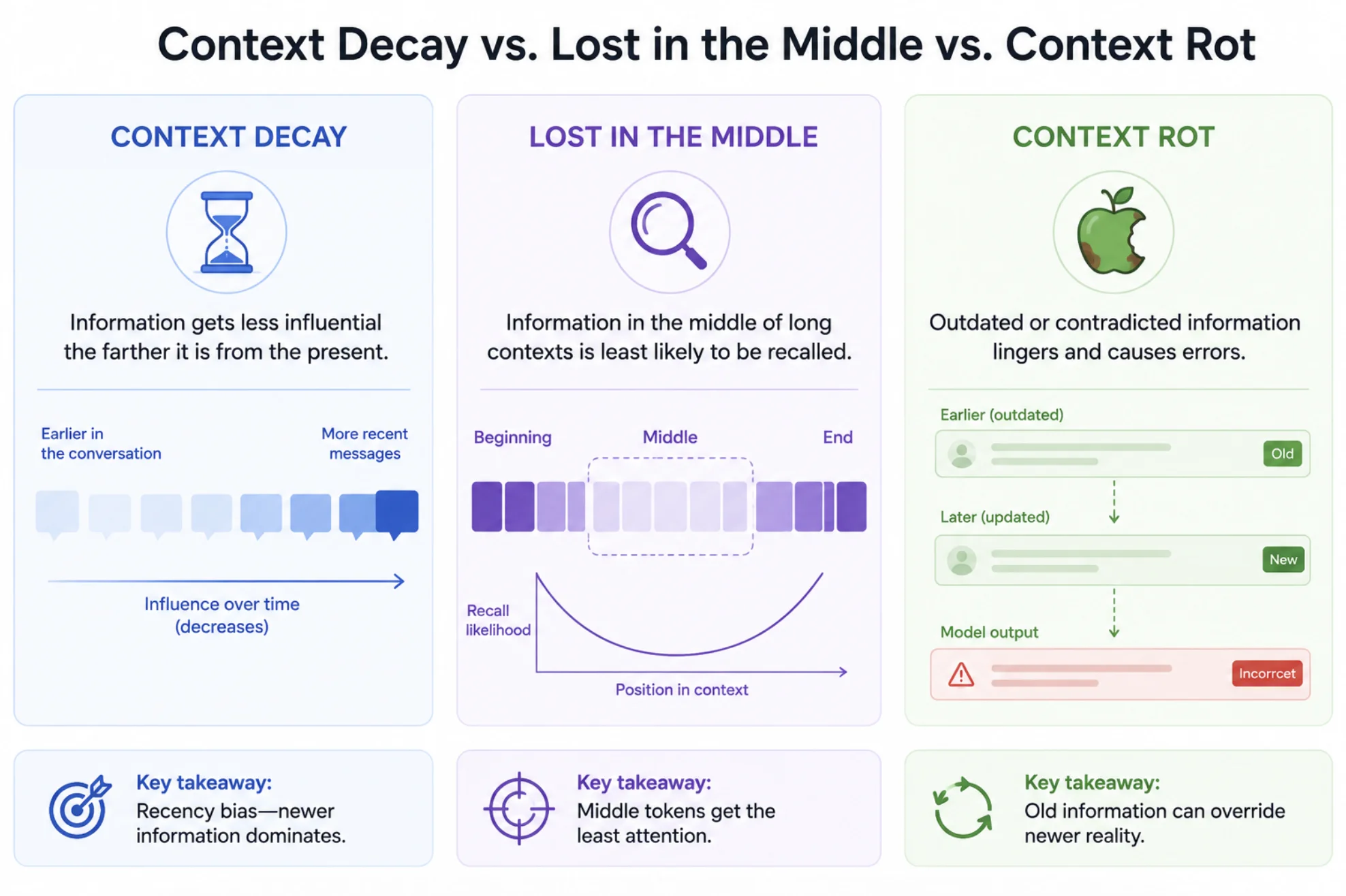
Context Decay vs. Context Rot vs. Lost in the Middle
These three terms get used interchangeably, but they describe distinct (overlapping) phenomena. Understanding the difference helps you diagnose what's actually going wrong.
| Term | What it describes | Primary cause |
|---|---|---|
| Context decay | Early instructions lose influence as context grows | Distance between instruction and generation point |
| Lost in the middle | Facts buried in the center of a prompt are recalled worst | U-shaped attention favoring start and end |
| Context rot | Overall output quality degrades as total input length increases | Token volume itself, even below the window limit |
Lost in the Middle
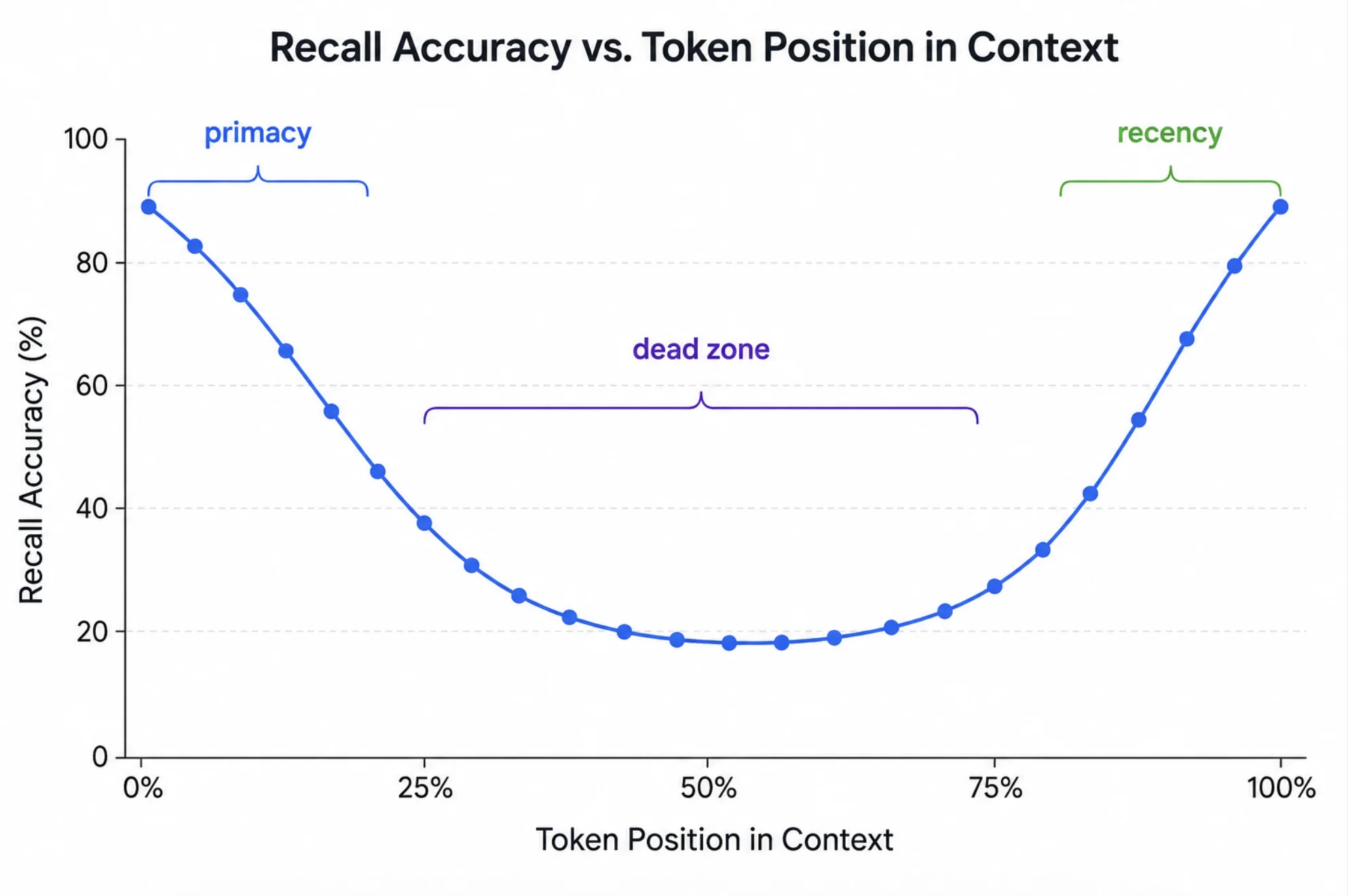
Research has consistently shown that LLM recall follows a U-shaped curve: models attend well to the beginning and end of a context, but accuracy plummets for information in the middle. A fact placed in the center of a long prompt can be 30% or more likely to be retrieved than the same fact at either edge.
Context Rot
In 2025, Chroma's research team formalized context rot after testing 18 frontier models — including GPT-4.1, Claude Opus 4, and Gemini 2.5. They found that every model degrades as input length grows, even when the context window is nowhere near full. Simply adding more tokens makes performance worse.
Context decay is best understood as the instruction-following slice of these broader effects: it's specifically about directions and constraints losing force, not just facts being hard to retrieve.
Why Context Decay Happens: The Mechanics
Context decay isn't a bug to be patched — it's an emergent property of how transformer attention works. Three mechanisms drive it.
1. Attention Dilution
A transformer's attention is a finite resource spread across every token in the context. With 500 tokens, your instruction competes with 499 others. With 100,000 tokens, it competes with 99,999. The relative "share of attention" any single early instruction can claim shrinks as the context fills up.
2. Positional Encoding and Distance Decay
Most modern LLMs use rotary positional embeddings (RoPE), which introduce a distance-based decay: tokens far apart have their attention scores naturally reduced. When the model is generating its response at the end of the context, instructions at the very beginning are maximally distant — and structurally discounted.
3. Recency and Primacy Bias
Two competing biases shape what survives:
- Recency: tokens nearest the generation point (the end) have the strongest, freshest signal.
- Primacy/attention sinks: the very first tokens get reinforced because models learn to use them as stable anchors.
Information caught between these two poles — neither recent nor first — falls into a dead zone. An instruction at the start gets some primacy protection, but once a long body of text pushes it far from the answer, recency wins, and the early rule decays.
This is why RAG pipelines place the highest-confidence documents at the very start and very end of the assembled context, not the middle.
How to Detect Context Decay in Your Application
Before fixing it, confirm it's happening. Watch for these signals:
- Format drift — the model starts obeying your output format (JSON, markdown, word count) and abandons it deep into long responses or long chats.
- Constraint leakage — safety or policy rules set in the system prompt get violated only in extended conversations.
- Persona slippage — a defined tone or role degrades the longer the session runs.
- Position-sensitive accuracy — moving the same instruction nearer the end suddenly "fixes" the behavior. This is the clearest diagnostic test.
A simple A/B check: run the same task with the instruction at the top versus repeated at the bottom. If the bottom placement performs noticeably better, you have context decay.
7 Proven Strategies to Prevent Context Decay
You can't eliminate the underlying attention dynamics, but you can engineer around them. Here are seven battle-tested techniques.
1. Put Critical Instructions Last
The single most effective fix. Place your most important constraints immediately before the model's turn to respond, after any long reference material. The end of the context has the strongest recency signal.
[Long document or chat history]...---REMINDER: Respond only in valid JSON. Do not include account numbers.Now answer the user's question.2. Bookend Your Instructions
Combine primacy and recency: state the rule at the top and restate it at the bottom. This "instruction sandwich" protects against decay from both directions.
3. Re-Inject Instructions Periodically
In long chats and agentic loops, re-insert the system rules every few turns rather than relying on the original message to survive. Many AI agent frameworks do this automatically.
4. Compress and Summarize History
When a conversation grows long, replace verbose earlier turns with a tight summary. Fewer tokens means less attention dilution and less context rot. Keep the summary near the top as a durable anchor.
5. Use Structured Delimiters
Wrap instructions in clear, consistent markers (### INSTRUCTIONS ###, XML tags, or all-caps headers). Strong visual structure helps the model relocate and re-attend to rules even at a distance.
6. Shorten the Context Window
The most underrated fix: send less. Because context rot scales with total token count, aggressive retrieval and pruning often beat stuffing everything in "just in case." Quality of context beats quantity.
7. Chunk Long Tasks
For very long documents, split the work into smaller sub-tasks, each with its own fresh, short context and its own copy of the instructions. Then aggregate the results. This sidesteps decay entirely.
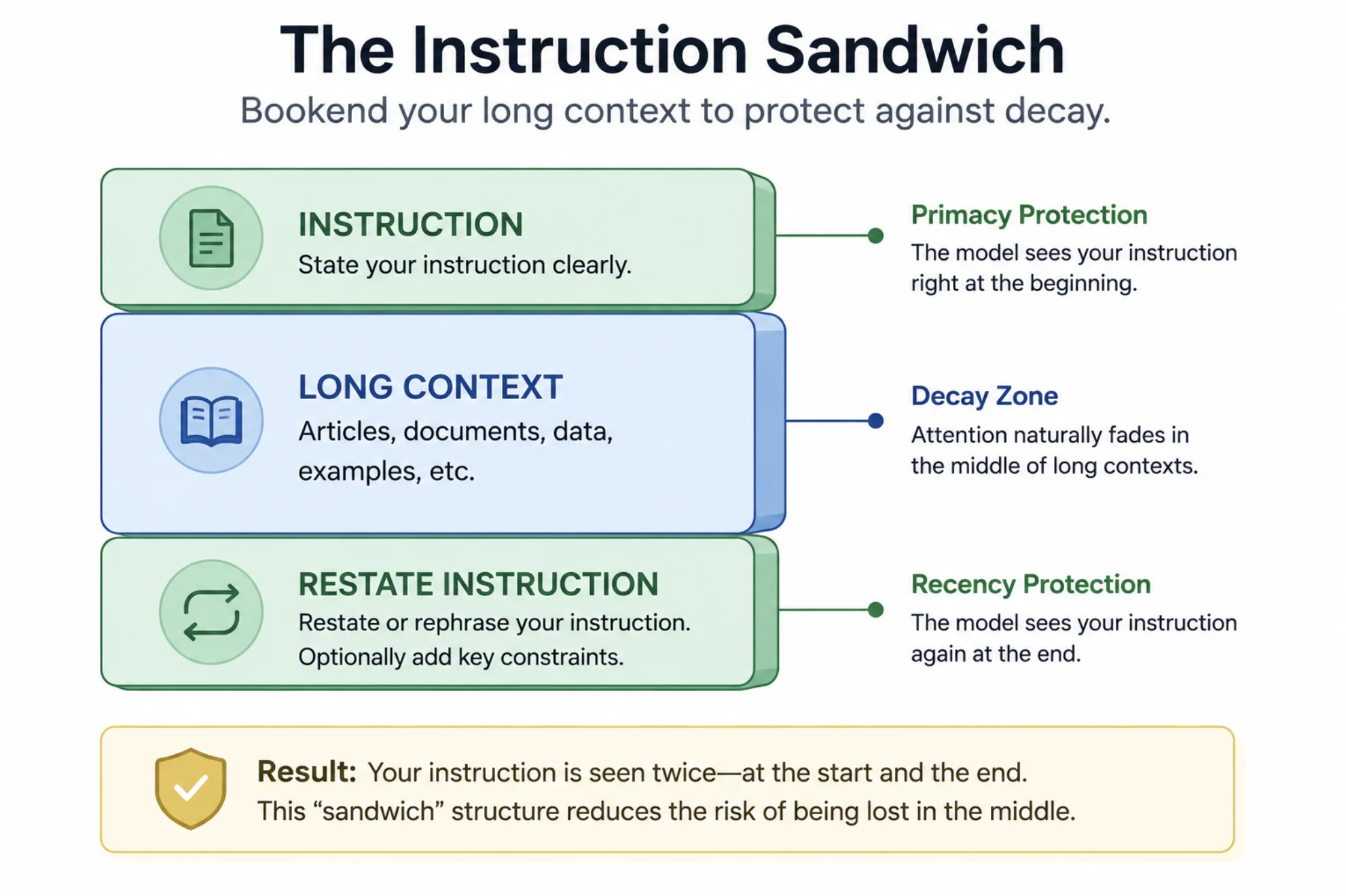
A Quick Before-and-After Example
Decay-prone prompt:
Summarize the following in exactly 3 bullets.[80,000 tokens of source text]Decay-resistant prompt:
TASK: Summarize the source text below in exactly 3 bullets.[80,000 tokens of source text]---REMINDER OF TASK: Output exactly 3 bullet points. No preamble.The second version bookends the instruction and gives it the recency boost it needs to survive the long body of text.
FAQ
What is context decay in LLMs?
Context decay is an LLM's tendency to "forget" or under-weight instructions placed far from where it generates its answer — usually at the start of a long prompt or chat. The instruction stays in the context window, but its influence on the output fades as surrounding tokens accumulate.
Is context decay the same as a context window limit?
No. A context window limit is a hard cap on how many tokens the model can read at once. Context decay happens within that limit — instructions can be fully inside the window and still lose their effect because of attention dynamics and position.
Where should I put the most important instructions?
At the end of the prompt, immediately before the model responds, because the end has the strongest recency signal. For extra reliability, also state the instruction at the very beginning so it benefits from primacy too — the "instruction sandwich" approach.
Does a bigger context window fix context decay?
Not on its own. Research on context rot shows that adding more tokens tends to worsen performance, even when the window isn't full. Larger windows let you fit more in, but they don't make the model attend to early instructions any better — they often make it worse.
How do I test whether my prompt suffers from context decay?
Run the same task twice: once with the instruction at the top, once with it repeated at the bottom. If bottom placement noticeably improves compliance, context decay is affecting your output.
Conclusion
Context decay is not a sign of a broken model — it's a predictable consequence of how transformer attention distributes itself across long inputs. Instructions at the beginning of a long document or chat history compete with everything that follows, sit far from the generation point, and slowly lose their hold on the model's behavior.
The fix is rarely a better-worded instruction. It's better placement: put critical rules last, bookend them, re-inject them in long sessions, and ruthlessly trim the context you don't need. Treat position as a first-class part of your prompt design, and your AI will keep following the rules from the first token to the last.
Ready to make your prompts decay-proof? Explore our prompt engineering playbook for templates and patterns you can copy today.