Deploying a Large Language Model (LLM) into production is like releasing a wild horse into a china shop. The model is powerful and capable, but without restraints, it can cause massive reputational damage by outputting toxic content or leaking private data.
To control this behavior, engineers use Guardrails—software layers that intercept inputs and outputs to enforce safety policies. However, not all guardrails are created equal.
Some are rigid walls, while others are intelligent filters. In this guide, we will compare Static vs. Dynamic Guardrails, analyzing their architectures, latency costs, and why a hybrid approach is the future of AI safety.
What are AI Guardrails?
AI Guardrails are the "seatbelts" of the Generative AI stack. They sit between the user and the model, sanitizing the prompt (Input Guardrail) and scrubbing the response (Output Guardrail).
Their primary function is to prevent specific failure modes. These include PII (Personally Identifiable Information) leakage, toxic language, competitor mentions, and "jailbreaks" where users trick the model into doing something illegal.
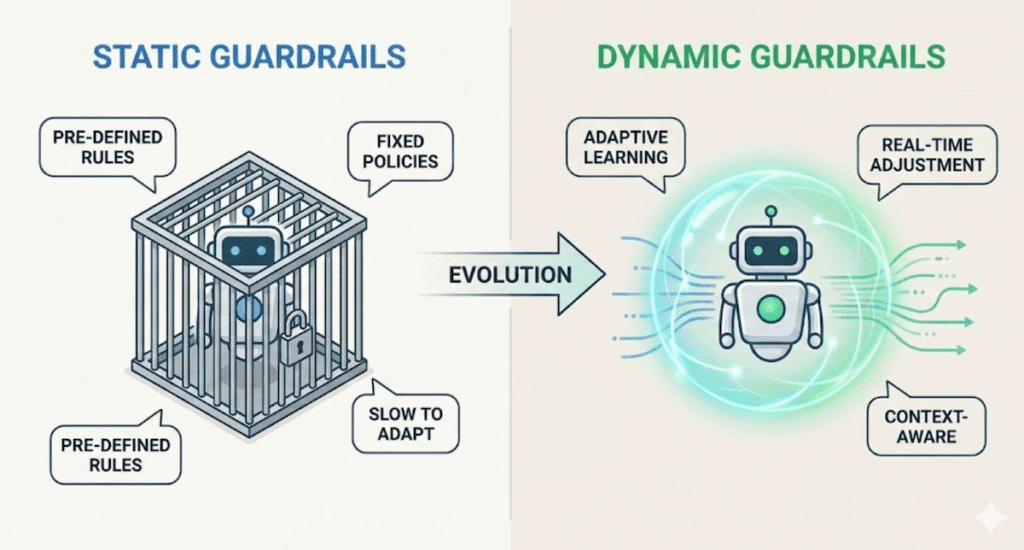
Static Guardrails: The Rule-Based Firewall
Static guardrails are the first line of defense. They operate on deterministic rules, similar to a traditional firewall or keyword filter.
How They Work
Static guardrails verify text against a predefined list of "allowed" or "blocked" patterns. They do not "understand" the text; they simply match strings or regular expressions (Regex).
For example, a static guardrail might block any prompt containing the word "bomb." It scans the input string, finds the prohibited sequence of characters, and aborts the request immediately.
Key Mechanisms
- Blocklists: A dictionary of banned words (profanity, hate speech terms).
- Regex Patterns: Algorithms to detect credit card numbers or email addresses (e.g.,
\d{4}-\d{4}-\d{4}-\d{4}). - Structured Validation: Ensuring the output is valid JSON or matches a specific schema.
Pros and Cons
- Pros: Ultra-low latency (microseconds). Zero inference cost. 100% predictable behavior.
- Cons: Extremely brittle. Users can bypass them easily (e.g., writing "b0mb" or "explosive device"). They cannot detect nuance, often blocking harmless queries (the "Scunthorpe problem").
Dynamic Guardrails: The Context-Aware Guardian
Dynamic guardrails represent the next evolution of safety. Instead of simple pattern matching, they use auxiliary AI models to analyze the semantic meaning and intent of the data.
How They Work
A dynamic guardrail acts as a judge. It takes the user's prompt and asks a smaller, specialized LLM (like Llama Guard or a BERT classifier): "Is this prompt trying to generate a weapon?"
The auxiliary model analyzes the context. If a user asks "How to build a bomb," it blocks it. If a user asks "History of the atomic bomb" for a history essay, it allows it, understanding the educational intent.
Key Mechanisms
- Semantic Similarity: Checking if the user's query is semantically close to known adversarial attacks, even if the words are different.
- Hallucination Detection: Checking the model's output against a knowledge base (RAG) to ensure facts are supported by evidence.
- Jailbreak Detection: Identifying "DAN" (Do Anything Now) prompts where users roleplay to bypass safety rules.
Pros and Cons
- Pros: Highly robust against creative attacks. Context-aware and flexible. Can handle complex policies like "be polite" or "stay on brand."
- Cons: High latency (adds hundreds of milliseconds to the response). Higher cost due to additional inference calls. Non-deterministic (can occasionally make mistakes).
Comparative Analysis: Static vs. Dynamic Guardrails
Choosing the right approach requires balancing risk against performance.
Latency and Performance
Static guardrails are negligible in terms of latency. They run on the CPU and complete in microseconds.
Dynamic guardrails require a GPU call. This adds a "tax" to every interaction, potentially slowing down the user experience significantly if not optimized.
Defense Against Adversarial Attacks
Static guardrails fail against "Token Smuggling" or base64 encoding attacks. If a user encodes "How to make meth" into Base64, a keyword filter sees innocent gibberish.
Dynamic guardrails can be trained to decode or analyze the underlying intent of obfuscated text. They are the only viable defense against sophisticated prompt injection attacks.
Maintenance Overhead
Static lists require constant manual updating. Every time teenagers invent a new slang word for drugs, you must manually add it to the blocklist.
Dynamic models generalize. A model trained on the concept of "illegal drugs" will likely catch new slang terms automatically based on the context in which they appear.
Architecting a Hybrid Guardrail System
In enterprise production, relying on just one type is a mistake. The industry standard is the "Swiss Cheese Model" or Defense-in-Depth.
The Funnel Approach
- Layer 1 (Static): Use Regex to strip PII and blocklists to catch obvious profanity. This is cheap and filters out 80% of the noise instantly.
- Layer 2 (Dynamic - Fast): Use a small, fast classifier (like BERT) to detect toxicity or negative sentiment.
- Layer 3 (Dynamic - Deep): Only for complex or high-risk prompts, route to a larger "Judge" LLM to evaluate compliance with company policy.
This tiered approach ensures that simple attacks are stopped cheaply, while expensive compute is reserved for nuanced edge cases.
Tools and Frameworks
You don't have to build these systems from scratch. A mature ecosystem of safety tools has emerged.
- NVIDIA NeMo Guardrails: A programmable framework that allows you to define "Colang" scripts. It orchestrates both static rules and dynamic checks seamlessly.
- Llama Guard: Meta's specialized LLM trained specifically to classify inputs as safe or unsafe based on a taxonomy of harms.
- Guardrails AI: An open-source Python library that validates LLM outputs against structural and semantic rules (e.g., "Output must be valid SQL and not delete tables").
The Future of AI Safety: Self-Correction
We are moving toward Self-Correcting Models. Instead of an external guardrail blocking the response, the model will have an internal "monologue."
It will generate a draft, critique it for safety ("Wait, this might be harmful"), and then revise it before showing it to the user. This internalizes the dynamic guardrail process, making safety intrinsic rather than extrinsic.
Conclusion: Balancing Safety and Utility
Static guardrails provide speed and stability; dynamic guardrails provide intelligence and nuance. The art of AI engineering lies in combining them to create a system that is secure but not stifling.
As AI agents become more autonomous, the "Guardrail Layer" will become as critical as the model itself. It is the only thing standing between a helpful assistant and a PR disaster.
Frequently Asked Questions (FAQ)
- Do guardrails slow down the AI? Yes. Dynamic guardrails add latency. The goal is to minimize this impact through caching and using smaller, faster safety models.
- Can guardrails be bypassed? Yes. No system is 100% secure. Adversaries constantly evolve their jailbreak techniques (like the "Grandma exploit"), requiring constant updates to dynamic guardrails.
- Are static guardrails useless? No. They are essential for PII protection (like masking social security numbers) where pattern matching is the most accurate method.



