Most production agent stacks carry the same architectural debt: a vector store bolted on for retrieval, a relational table for chat history, hand-written extraction prompts to convert conversations into facts, and bespoke isolation logic layered on top of all of it. Each piece has its own credentials, its own backup story, and its own compliance review. When something goes wrong, you debug four systems.
Oracle AI Agent Memory, available as oracleagentmemory on PyPI, replaces that fragmented stack with a single Python SDK backed by Oracle AI Database. This article covers the four-memory-type architecture, the storage primitives the SDK manages, the token cost mechanics, and what the benchmark numbers actually mean for how you configure the system.
The Four-Memory-Type Architecture of Oracle AI Agent Memory
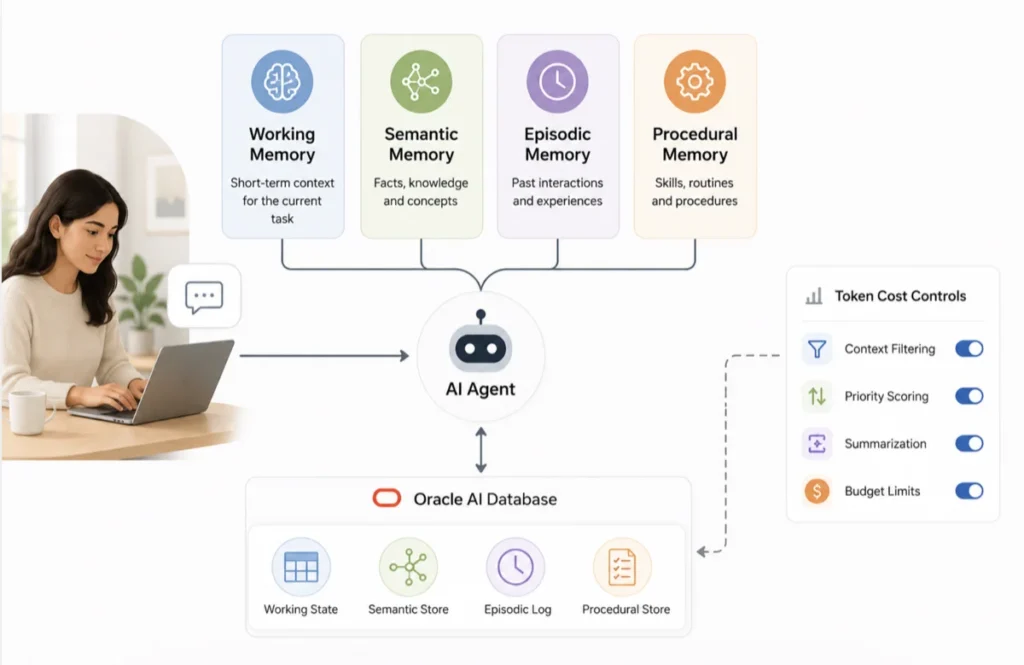
The SDK organizes agent state into four categories that correspond to different access patterns, not different systems. All four types write to the same Oracle AI Database backend and share one retrieval surface. The distinction is semantic, not infrastructural.
Working memory is the active in-context state: the running conversation thread and the scratchpad the model sees at inference time. It is bounded and ephemeral by design. Semantic memory is the durable facts an agent accumulates over time: user preferences, entity data, and canonical definitions. It persists across sessions and is searchable via vector similarity.
Episodic memory captures specific past experiences: what a user asked three weeks ago, how a similar task was resolved, and what a prior session concluded. Procedural memory encodes behavioral rules and learned guidelines: which tools to prefer, how to handle specific customer situations, and what not to do in a given context.
| Memory Type | Persistence | Primary Access Pattern | Example Content |
|---|---|---|---|
| Working | In-context only | Sequential thread read | Active conversation, in-flight task state |
| Semantic | Durable, cross-session | Vector similarity search | User preferences, entity facts |
| Episodic | Durable, timestamped | Temporal and semantic retrieval | Prior session outcomes, resolved tasks |
| Procedural | Durable, versioned | Rule lookup, vector similarity | Behavioral guidelines, tool preferences |
Oracle AI Database as the Storage Backend
Oracle AI Database serves the retrieval requirements across all four memory types from a single engine. Vector similarity search handles semantic and episodic retrieval. Relational queries handle precise lookups by user ID, thread ID, agent ID, and timestamp. Graph traversal handles relationship-centric queries across entity data. JSON document storage handles schemaless memory payloads.
This convergence is the architecturally significant choice here. A typical multi-service memory stack couples a vector database, a relational store, and sometimes a document store, each with independent scaling, replication, and backup configurations. Putting all four access patterns on one engine means one point of backup, one replication configuration, one encryption policy, and one audit trail. If you already run Oracle AI Database for other workloads, your agents write to the same governed backend you already have compliance coverage for.
Installing and Initializing the SDK
Install the package with pip install oracleagentmemory. The entry point is AgentMemory.from_connection(), which takes a connection string targeting your Oracle AI Database instance and a user_id that scopes all subsequent reads and writes to that user's isolated partition.
Every operation the SDK exposes, thread creation, message ingestion, memory extraction, and search, inherits the user scope from the client instance. Cross-user reads are not possible through the SDK surface without explicitly constructing a new client scoped to a different user, which is the isolation guarantee that makes a single database schema safe to use for multiple deployments.
Thread Management and Message Ingestion in Oracle AI Agent Memory
A thread is the working memory container for a conversation session. You create one with memory.create_thread(user_id="...") and write turns into it with memory.add_messages(thread_id, messages=[...]). Each message in the list is a role-content dictionary matching the standard chat completion message format, so you can pass turns directly from your LLM response objects without transformation.
The thread lives in the database and survives process restarts. If your agent process crashes mid-session, you reconstruct the thread by reading it back by ID rather than relying on in-memory conversation state. This is the key behavioral difference from frameworks that maintain conversation history in a Python list: the durability is at the storage layer, not the process layer.
LLM-Based Memory Extraction
Calling memory.extract_memories(thread_id) triggers an LLM pass over the thread that identifies facts worth promoting to long-term storage. The SDK handles the extraction prompt internally; you do not write or maintain the extraction chain. The extracted facts are written as durable memory records scoped to the user and agent, queryable via vector similarity on subsequent sessions.
The extraction model is configurable. You specify the LLM client and model identifier at SDK initialization time, and the extraction call uses that configuration. This means the model doing extraction does not have to be the same model driving the agent's reasoning, which lets you use a smaller, cheaper model for extraction without degrading reasoning quality.
Scoped Search and Retrieval
Long-term memory search uses memory.search(user_id="...", query="...", limit=N). The user_id argument is enforced at the query layer, not just at application logic. Records belonging to other users are not returned regardless of query content. This is the enforcement boundary that makes multi-tenant deployments viable without bespoke row-level security implementations on top of the vector store.
The search executes vector similarity over the memory record embeddings and returns the top-K results ranked by relevance score. The limit parameter sets K. The returned records include the full memory content, the source thread ID, and the timestamp of extraction, which gives downstream reasoning layers enough context to assess memory recency.
Thread Summarization and Token Cost Control
The most operationally important tuning parameter in the SDK is the summarization trigger threshold. When a thread exceeds the token threshold you configure, the SDK condenses older turns into a summary and extracts durable memories from the compacted content. The full verbatim history is replaced in the working context by the summary plus a retrieved context card of the most relevant long-term memories for the current turn.
The benchmark data from the announcement illustrates how significant this effect is. Across an 80-turn conversation, an unmanaged flat-history agent reached approximately 13,900 input tokens per request by the final turn. With Oracle AI Agent Memory managing the thread, per-request input held steady at approximately 1,300 tokens for the entire run. That is roughly a 9.5x token reduction at the tail of a long session, which directly maps to a 9.5x cost difference on input tokens for those turns.
The threshold is a cost-fidelity trade-off. A 10,000-token trigger produces aggressive compaction and the lowest total token spend across a session, approximately 121,000 tokens in the benchmark's 8-query test against a 306,000-token flat-history baseline. As you raise the trigger to 50,000 or 70,000 tokens, compaction happens less frequently, more raw context is preserved per turn, and total token spend converges toward the unmanaged baseline. The right threshold depends on how much verbatim context precision your specific use case requires.
Answer Quality Under Memory Management
A counterintuitive concern with summarization-based memory is that compacting history should hurt recall accuracy, because the flat-history agent has the complete verbatim transcript available. The benchmark results from the announcement address this directly. Across the same 80-turn conversation evaluated by an independent LLM judge on accuracy, completeness, relevance, and coherence, Oracle AI Agent Memory won 48 turns against flat history's 13, with 19 ties.
The mechanism behind this is attention dilution. A flat-history agent's context grows continuously with irrelevant, repetitive, or superseded content alongside the relevant facts. A retrieved context card surfaces only the semantically relevant memory records for the current query. A focused 1,300-token context outperforms a 13,900-token transcript because the model's attention is not distributed across noise.
LongMemEval Benchmark Results
LongMemEval is the standard academic benchmark for evaluating long-context agent memory across five categories. Oracle AI Agent Memory scored 93.8% overall (469 of 500) in the benchmark configuration using OpenAI gpt-5.5 at reasoning effort xhigh, nomic-embed-text-v1.5 embeddings, a local HNSW index, and top-K set to 200.
The per-category scores are worth examining individually. Single-session assistant recall scored 100%, which establishes that the SDK loses nothing within a single conversation. Temporal reasoning scored 96.2%, knowledge update tasks scored 94.9%, single-session user preference recall scored 93.3%, and multi-session recall, which is the hardest category because it requires coherent memory across separate conversation threads, scored 88%. The multi-session result is the most useful number for production planning because it reflects how the system performs across the session boundaries that real agents routinely cross.
Audit, Erasure, and Compliance Primitives
Every memory record the SDK writes carries four scoping fields: user_id, agent_id, thread_id, and a creation timestamp. The SDK exposes search, list, and per-record delete operations across memories, threads, and messages. To locate and remove all records for a given user, you issue a scoped list by user_id and then call delete on each returned record.
Oracle AI Database's native auditing operates at the storage layer underneath the SDK. Database-level audit logs capture reads and writes on the memory tables independently of what the SDK exposes. This means your compliance posture does not depend solely on application-layer logging. The audit trail exists even if the application is bypassed, which is a meaningful distinction from memory stacks built on purpose-built vector stores without native database audit capabilities.
Framework Integration
The SDK is framework-agnostic. You instantiate the same OracleAgentMemory client regardless of whether your agent runtime is LangGraph, the Claude Agent SDK, the OpenAI Agents SDK, WayFlow, or a custom Python harness. All runtimes read from and write to the same Oracle AI Database store, which means you can run multiple agent frameworks against a shared memory substrate without duplicating data or maintaining per-framework memory pipelines.
This also means framework migrations do not require memory migrations. If you move an agent from one runtime to another, the memory state in Oracle AI Database persists and remains accessible through the same SDK calls. The framework switch is an application-layer change; the memory layer is unaffected.
Conclusion
The core engineering value of Oracle AI Agent Memory is replacing a four-service memory stack with one governed backend that handles vector search, relational scoping, and JSON storage in the same engine you already use for structured data. The token efficiency numbers are the most immediately actionable result: a flat summarization configuration reduces per-request input tokens by roughly 9.5x at session tail compared to unmanaged flat history, and does so without measurably degrading answer quality.
The tuning surface is narrow and intentional. Set your summarization threshold based on the cost-fidelity trade-off your workload requires, configure your extraction model separately from your reasoning model if you want to optimize spend on extraction, and scope all client instances to their user IDs at initialization to get tenant isolation without any additional application logic on top.