Most databases store what is happening right now. But what if you need to know what was true yesterday, or what your system believed to be true last month, even if that belief turned out to be wrong? A bitemporal database solves exactly that problem by tracking two separate timelines at once.
This concept shows up constantly in industries where auditing and data accuracy are non-negotiable. Finance, healthcare, insurance, and legal systems all depend on the ability to reconstruct the state of data at any point in time. Understanding how bitemporal data modeling works will change how you think about database design entirely.
The Two Timelines in a Bitemporal Database
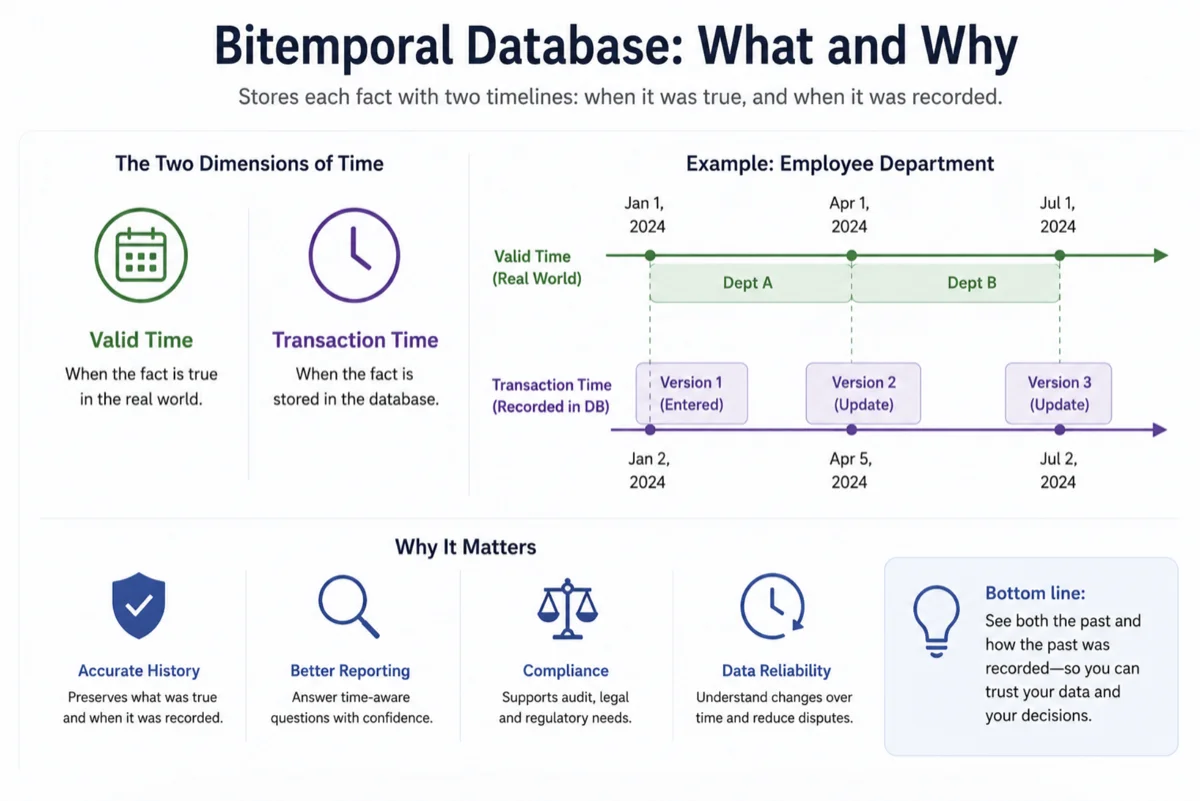
The core idea behind a bitemporal database is managing two distinct time dimensions simultaneously. Each one answers a completely different question about your data.
The first dimension is called valid time. This is when a fact was actually true in the real world. The second is called transaction time, sometimes called system time. This records when your database learned about that fact.
These two timelines are independent of each other. A fact can be valid in the real world long before your system knows about it, and a correction recorded today can affect a period that started years ago. Separating these timelines is what makes bitemporal modeling so powerful.
"In a world of constant change, the most important question is not just what changed, but when it changed and when you knew about it." — Richard Snodgrass, pioneer of temporal database research
Valid Time vs. Transaction Time: A Clear Comparison
These two time dimensions are easy to confuse at first. The table below breaks down the key differences so you can see exactly how each one works.
| Dimension | Also Known As | What It Records | Who Controls It |
|---|---|---|---|
| Valid Time | Application Time | When a fact was true in the real world | The application or user |
| Transaction Time | System Time | When the database recorded the fact | The database engine (automatic) |
Why a Standard Database Falls Short
A traditional database only knows the current state of your data. When you update a row, the old value disappears. When you delete a record, it is gone forever. There is no built-in way to ask "what did this record look like on January 15th?"
Many teams try to work around this by adding a single updated_at column or maintaining a separate audit log table. These approaches feel familiar, but they only capture one dimension of time and often lack the structure needed for reliable historical queries.
The real gap shows up when you need to correct a past error. Say an employee's salary was entered incorrectly for a three-month period. A standard audit log tells you what changed, but a bitemporal table tells you the corrected salary history as it should have been, alongside the record of what the system actually held during that period.
A Real-World Example: Insurance Policy Updates
Imagine a health insurance company needs to update a customer's coverage level, effective six months ago, because a billing error was discovered today. With a regular database, this is a painful manual process. With a bitemporal database, you simply record the corrected valid time period, and the transaction time automatically captures when you made that correction.
Now the system can answer two separate questions: "What was the customer's coverage on March 1st?" and "What did we think the coverage was on March 1st, as of last week?" These are genuinely different questions, and both answers can matter enormously in a dispute or audit.
How Bitemporal Tables Are Structured
A bitemporal table adds four columns to your schema to manage both time dimensions. These columns define the start and end of each period for both valid time and transaction time.
Here is a simplified structure for a bitemporal employee salary table to illustrate the pattern.
CREATE TABLE employee_salary_history (
employee_id NUMBER,
salary NUMBER,
-- Valid Time: when the salary was true in the real world
valid_start DATE,
valid_end DATE,
-- Transaction Time: when the database recorded this row
txn_start TIMESTAMP DEFAULT SYSTIMESTAMP,
txn_end TIMESTAMP DEFAULT TO_TIMESTAMP('9999-12-31', 'YYYY-MM-DD')
);
The txn_end column is typically set to a far-future sentinel value, like December 31, 9999, to indicate the current version of a record. When a row is superseded by a correction, you close off the old row by setting its txn_end to the current timestamp, and then insert a new row with the corrected data.
Querying Across Both Timelines
Once your table is structured this way, your queries become very precise. You can ask the database to return the state of the data as of any combination of real-world time and system knowledge time.
-- What did the system believe about employee 101's salary on March 1st,
-- as recorded by April 15th?
SELECT salary
FROM employee_salary_history
WHERE employee_id = 101
AND valid_start <= DATE '2025-03-01'
AND valid_end > DATE '2025-03-01'
AND txn_start <= TIMESTAMP '2025-04-15 00:00:00'
AND txn_end > TIMESTAMP '2025-04-15 00:00:00';
This kind of query is impossible to express cleanly with a single-timestamp audit log. Bitemporal tables make it straightforward and reliable.
SQL:2011 Standard and Modern Database Support
Bitemporal database concepts are not just theoretical. The SQL:2011 standard formally introduced support for temporal tables, including both application-time and system-time period definitions. This gave the database industry a common language for implementing these features.
Several major database systems now offer built-in support for temporal features, though the level of support varies by platform.
- MariaDB supports system-versioned tables, which handle transaction time automatically
- IBM Db2 has offered full bitemporal table support since version 10.1
- Microsoft SQL Server supports temporal tables with system-time versioning
- Oracle Database supports valid time and system time through Workspace Manager and Flashback features
- PostgreSQL relies on community extensions like temporal_tables for this functionality
"Temporal databases solve problems that most developers don't even realize they have, until the first audit fails." — Joe Celko, author of SQL for Smarties
Bitemporal Data Modeling Challenges
Adopting a bitemporal approach comes with trade-offs you should plan for. Storage requirements increase because you keep every version of every row and never truly delete anything. Query complexity also rises, since every lookup involves range conditions on two separate period columns.
Schema design becomes more deliberate as well. You need to define clear rules for how your application handles overlapping valid time periods and how corrections get recorded without creating contradictory rows. Getting this right upfront saves a significant amount of pain later.
Key Design Principles for Bitemporal Tables
Before you build your first bitemporal table, keep these principles in mind to stay on solid ground.
- Never physically delete rows; always close them by updating the transaction end timestamp
- Use a far-future sentinel value (like year 9999) to mark currently active records
- Add database constraints to prevent overlapping valid time periods for the same entity
- Create indexes on both the valid time and transaction time columns for query performance
- Document your correction workflow clearly so all team members apply it consistently
When Should You Use a Bitemporal Database?
Not every application needs this level of temporal precision. A simple blog or a product catalog does not require tracking two timelines. But if your data has any of the following characteristics, bitemporal modeling is worth serious consideration.
- Regulatory requirements mandate a full, unalterable history of all data changes
- Your business domain involves backdated corrections, such as payroll adjustments or insurance claims
- Users need to generate reports "as of" a specific date in the past
- Auditors must be able to verify what the system believed at any point in time
- Your application manages contracts, policies, or agreements with defined effective dates
If your project meets even two or three of those criteria, the upfront investment in bitemporal design will pay off quickly. The alternative is typically a fragile set of manual workarounds that breaks down under audit pressure.
Conclusion
A bitemporal database gives you something a conventional database simply cannot: a complete and trustworthy record of both what happened in the real world and when your system came to know about it. By separating valid time from transaction time, you gain the ability to correct the past without erasing it, satisfy auditors without scrambling, and answer historical questions with precision. If you work in any domain where data accuracy and accountability are critical, bitemporal data modeling is one of the most valuable patterns you can add to your toolkit.