When you build complex applications, managing how data gets saved can become a huge headache. You might find yourself writing code that constantly opens and closes database connections. This scattered approach often leads to messy code and serious data inconsistencies.
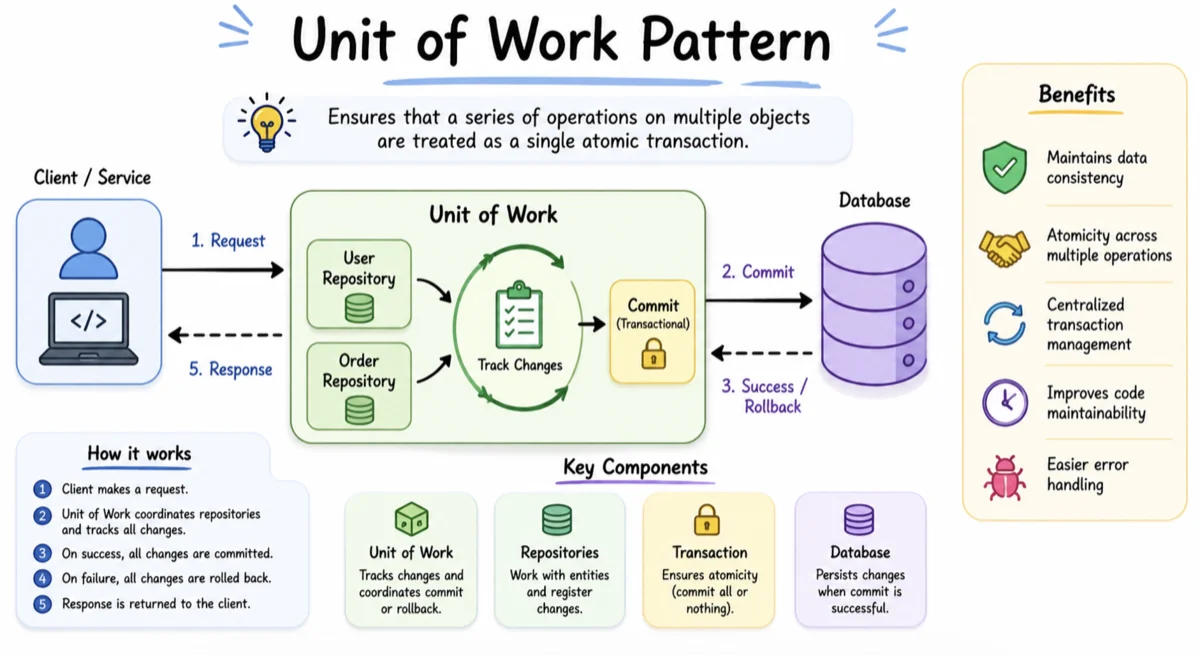
The Unit of Work pattern exists to solve exactly these kinds of data management problems. This software architecture concept acts as a central coordinator for all your database operations. It ensures that your application handles data changes smoothly and reliably.
In this article, you will learn how the Unit of Work design pattern can transform your data access layer. You will discover how it keeps your enterprise application architecture clean and organized. By the end, you will know exactly how to apply this concept to your own projects.
What is the Unit of Work Pattern?
The Unit of Work pattern is a fundamental design pattern in software engineering. It maintains a list of objects affected by a business transaction. It coordinates the writing out of changes and resolves concurrency problems.
Imagine you go to a grocery store and pick up several items. You do not pay for each item individually as you place it in your shopping cart. Instead, you take everything to the checkout counter and pay for it all in one single transaction.
This is exactly how the Unit of Work pattern operates within your software architecture. It tracks all the changes you make to your data throughout a process. Then, it commits all those changes to the database simultaneously in a single database transaction. A Unit of Work keeps track of everything you do during a business transaction that can affect the database.
By keeping track of all changes in memory, your application avoids touching the database until it absolutely has to. This tracking mechanism is the heart of how the pattern works. It is a deceptively simple idea that provides massive benefits for your codebase.
How the Unit of Work Design Pattern Functions
To understand this concept fully, you need to look at how data operations usually happen. Without a central coordinator, your application might try to save a user record, then a profile record, and then a settings record. If the server crashes before saving the settings, your data is now corrupted.
The Unit of Work pattern prevents this nightmare scenario entirely. It wraps all your individual operations into a protective shell. If any single operation fails, the entire transaction is cancelled through a process called a rollback.
This approach guarantees absolute data integrity for your software architecture. Your database will never be left in a halfway state again. Everything either succeeds completely or fails completely.
Managing State Changes in Memory
When you use this pattern, the unit of work object acts like an in-memory database. As you add, modify, or delete data objects, the unit of work simply marks them with their new state. It does not actually execute any SQL commands at this stage.
It maintains separate lists for new objects, dirty objects, and removed objects. This organized tracking system allows it to know exactly what needs to happen when you finally decide to save. It calculates the most efficient way to apply all these changes at once.
Comparing Approaches to Database Transactions
It helps to see the difference between the two approaches clearly. The table below outlines how data handling changes when you implement this design pattern.
| Feature | With the Unit of Work Pattern | With Unit of Work Pattern |
|---|---|---|
| Database Calls | Multiple separate round trips | One single coordinated trip |
| Failure Handling | Partial data gets saved | Automatic rollback of all changes |
| Performance | Slower due to many connections | Faster and highly optimized |
| Code Cleanliness | Scattered and hard to read | Centralized and easy to maintain |
Why You Need the Unit of Work Pattern
Adopting the Unit of Work pattern in your software architecture offers massive advantages. You will immediately notice improvements in how your application performs and how your code looks. It removes a lot of the friction associated with data management.
Here are the core benefits you will experience when you make the switch:
- It provides total data integrity by ensuring all related changes succeed or fail together.
- It significantly reduces database calls, which speeds up your application's response times.
- It prevents concurrency issues when multiple users try to modify the same data simultaneously.
- It decouples your business logic from the specific details of your database technology.
- It makes your code much easier to test because you can mock the entire unit of work.
Guaranteeing Complete Data Integrity
Data integrity is the absolute most important aspect of any software architecture. When your users trust you with their information, you cannot afford to lose or corrupt it. The Unit of Work pattern is your primary insurance policy against data corruption.
By enforcing a strict all-or-nothing rule, you eliminate the risk of orphan records. You never have to write messy cleanup scripts to fix halfway completed operations. Your data access layer becomes a fortress of reliability and consistency.
Reducing Unnecessary Database Calls
Every time your application talks to your database, it costs precious time and processing power. Opening connections and sending queries over a network is surprisingly slow. If you do this for every single data change, your application will crawl to a halt.
The Unit of Work pattern solves this performance bottleneck brilliantly. It stores all your changes in memory while you work on your business logic. When you are completely finished, it sends everything to the database in one massive, efficient batch.
Handling Concurrency Issues Gracefully
In web applications, you often have hundreds of users trying to change data at the same time. This creates concurrency conflicts where one user might accidentally overwrite the changes of another user. The Unit of Work pattern helps you manage these conflicts systematically.
Because all changes flow through a single point, you can implement checks to ensure data has not changed since you loaded it. If a conflict is detected, the unit of work can reject the transaction and notify you. This prevents silent data loss and keeps your application predictable.
Implementing the Unit of Work Pattern in Software Architecture
Putting this design pattern into practice is simpler than you might think. You usually start by creating an interface that defines the operations your unit of work will support. This interface typically includes methods for committing changes and rolling them back.
Then, you create a concrete class that implements this interface for your specific database. This class will hold references to all the data operations happening in your current request. It manages the actual database connection and handles the complex transaction logic.
When you write your business logic, you pass this unit of work object around to your different functions. Every component that needs to touch data uses this single shared object. This ensures everyone is participating in the exact same transaction from start to finish.
Example Code Implementation
Here is a basic example of how you might structure this in your code. This snippet demonstrates the core concept of coordinating changes across your application.
class UnitOfWork:
def __init__(self, database_session):
self.session = database_session
def commit(self):
try:
self.session.commit()
except Exception:
self.session.rollback()
raise
def rollback(self):
self.session.rollback()
You can see how simple the concept is at its core when looking at the code. The complexity of database management is hidden away behind a clean interface. Your main application code only ever needs to call that one commit method when it finishes.
Combining Unit of Work with the Repository Pattern
You will almost always see the Unit of Work pattern paired directly with the Repository pattern. These two concepts are essentially best friends in modern software architecture. They work perfectly together to create an incredibly powerful data access layer.
The Repository pattern handles the specific logic for querying and filtering your data records. It acts like an in-memory collection of your objects that you can search through. However, a repository should never save changes to the database on its own.
Instead, the repository registers its intended changes with the Unit of Work. The Unit of Work then takes full responsibility for actually saving those changes when the time is right. This strict separation of concerns keeps your code incredibly clean and modular. Repositories handle the queries, while the Unit of Work handles the transactions.
Creating a Solid Data Access Layer
When you combine these two patterns, you create a perfect boundary around your database. Your business logic never has to know about SQL queries or specific connection strings. It simply asks the repository for data and tells the Unit of Work to save any changes.
This approach makes your enterprise application architecture incredibly flexible and adaptable to change. If you ever need to change your database technology, you only update your repositories and your unit of work. The rest of your application logic remains completely untouched and functional.
Making Application Testing Much Easier
Writing automated tests for code that talks to a real database is notoriously slow and difficult. The Unit of Work pattern solves this testing problem by abstracting the database away completely. You can easily create a fake unit of work that stores data in memory for your tests.
This means your tests will run incredibly fast and will not depend on external database servers. You can test your business logic in total isolation from your infrastructure. This leads to a much more robust and reliable test suite for your application.
Advanced Considerations for the Unit of Work Pattern
While this design pattern is powerful, you do need to use it carefully and intentionally. Holding too many changes in memory can cause performance issues if you are not paying attention. You should try to keep your transactions as short and focused as possible.
You also need to think about how you handle long-running business processes. If a user needs to review changes before saving, you cannot keep a database transaction open the whole time. In those cases, you might need to use disconnected entities and attach them to a new unit of work later.
Finally, modern frameworks like Entity Framework or Hibernate often implement this pattern for you automatically. You might not need to write a custom unit of work class from scratch for every project. However, understanding how it works under the hood is still absolutely essential for any serious software architect.
Conclusion
The Unit of Work pattern is a critical tool for building robust and reliable software architecture today. It takes the chaos out of data management and replaces it with a clean, centralized system. By treating related operations as a single transaction, you guarantee total data integrity for your users.
You have seen how it reduces database calls and improves the overall performance of your application. You also understand how perfectly it pairs with the Repository pattern to create a seamless data access layer. Implementing these concepts will immediately elevate the quality of your entire codebase.
Take the time to analyze your current projects and see where data operations are scattered around. Introduce a unit of work to coordinate those changes and watch your codebase become much easier to maintain. Your future self will definitely thank you for making the effort to implement this powerful design pattern.