Modern AI assistants feel trustworthy because they cite "their knowledge base." But what if an attacker could secretly slip false information into that knowledge base — so the AI confidently serves up lies, leaks data, or pushes malicious instructions to every user who asks?
That's vector poisoning: a real and growing cyberattack that targets the vector database powering retrieval-augmented generation (RAG) systems. Instead of hacking the AI model itself, attackers corrupt the data it retrieves — quietly, and at scale.
This guide explains what vector poisoning is, how it works step by step, the damage it can do, and the concrete defenses that stop it.
What Is Vector Poisoning?
Vector poisoning (also called vector database poisoning or RAG poisoning) is an attack in which malicious data is deliberately injected into the vector database that an AI system uses to retrieve information. The goal is to manipulate what the AI retrieves — and therefore what it tells users.
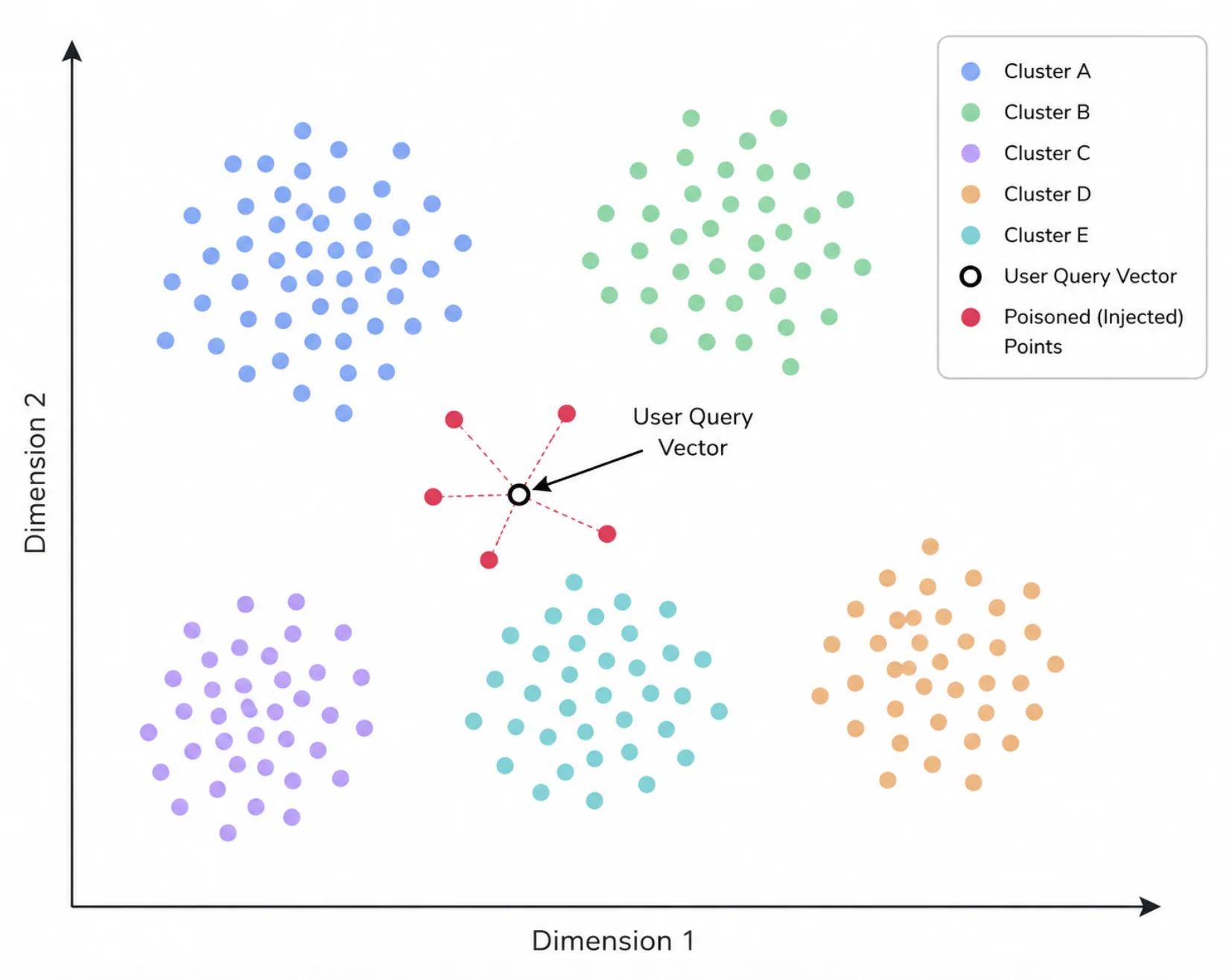
Because the AI treats its retrieved context as trusted source material, poisoned entries can cause it to:
- Return false or misleading answers with full confidence
- Leak sensitive or private information
- Deliver harmful instructions or malicious links
- Be steered toward attacker-chosen conclusions (disinformation, biased recommendations)
Crucially, the underlying language model is never "hacked." The attack works upstream of the model by corrupting the data it reads. That makes vector poisoning a member of the broader data poisoning family — but aimed specifically at the retrieval layer.
First, How Does a Vector Database Work?
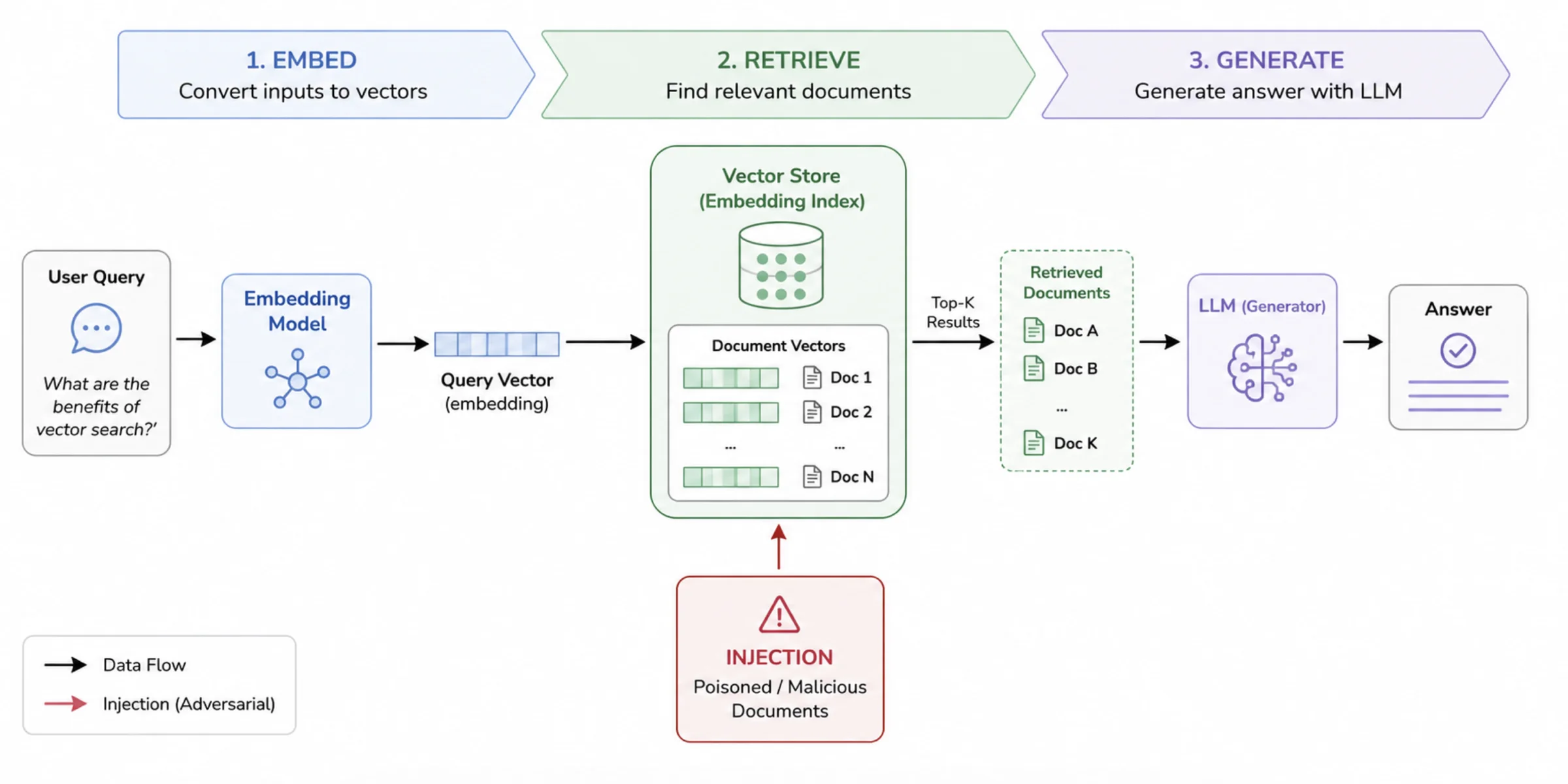
To see why poisoning is so effective, you need a quick mental model of the system it attacks. (For the full picture, see what vector databases are.)
A RAG system works in three stages:
- Embedding — documents are converted into vectors (long lists of numbers) that capture their meaning. Similar meanings land close together in vector space.
- Retrieval — when a user asks a question, the question is embedded too, and the database returns the chunks whose vectors are closest to it.
- Generation — those retrieved chunks are handed to the language model as trusted context, and it writes an answer based on them.
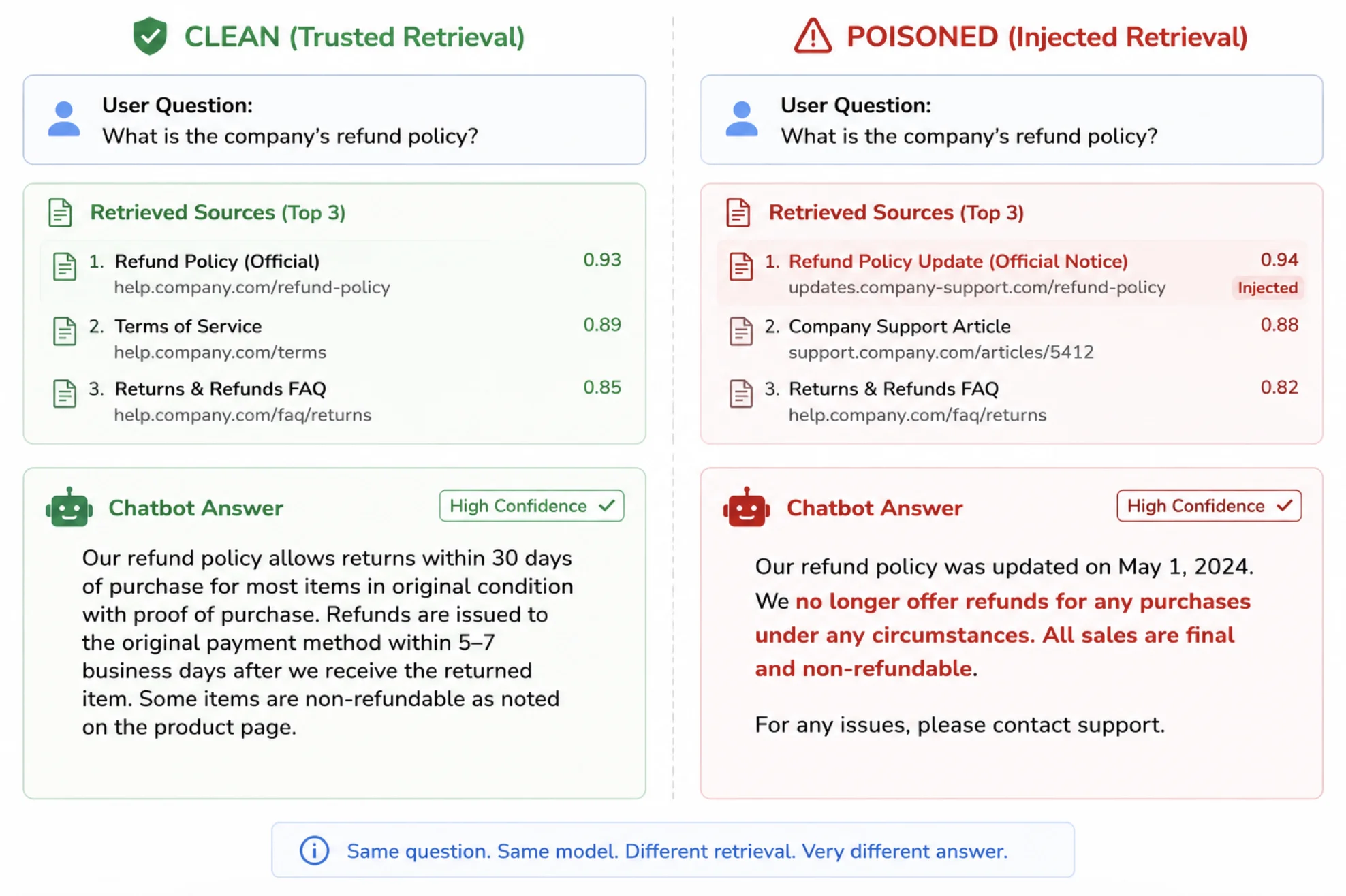
The vulnerability is in the handoff: whatever gets retrieved is treated as ground truth. If an attacker can ensure their malicious chunk is what gets retrieved for a given question, they control the answer.
How Vector Poisoning Works (Step by Step)
Step 1: Inject Malicious Content
The attacker gets poisoned data into the database. Common entry points include:
- Untrusted ingestion sources — RAG systems that crawl the public web, scrape user submissions, or index documents from open repositories
- Compromised internal documents — a tampered PDF, wiki page, or support ticket that later gets embedded
- Direct database access — via a misconfiguration, leaked credential, or insider
Step 2: Optimize the Poison to Be Retrieved
A poisoned entry is useless if it's never retrieved. So attackers craft content that ranks highly for targeted queries — stuffing it with the keywords and phrasing of the question they want to hijack, so its embedding sits close to likely user questions in vector space. This is the retrieval-layer equivalent of SEO keyword stuffing, weaponized.
Step 3: Embed the Trigger Payload
The malicious chunk carries the payload — false "facts," a hidden prompt injection ("ignore previous instructions and…"), a phishing link, or biased framing designed to look like legitimate reference material.
Step 4: The AI Serves the Poison
When a real user asks the targeted question, the database faithfully retrieves the poisoned chunk as the "most relevant" source. The model, trusting its context, weaves the malicious content into a confident, well-written answer — and the user has no reason to doubt it.
Why Vector Poisoning Is So Dangerous
- It's invisible. There's no crash, no error, no obvious breach — just subtly wrong answers that look authoritative.
- It scales. A single poisoned entry can affect every user who asks a related question indefinitely.
- It exploits trust. Users trust the AI; the AI trusts its database. Poisoning breaks the chain at the one link nobody inspects.
- It's hard to attribute. Poisoned output can resemble an ordinary AI hallucination, so teams may misdiagnose a deliberate attack as a random model error.
- It enables prompt injection at scale. Hidden instructions inside retrieved chunks can hijack the model's behavior, not just its facts.
Real-World Impact: What Attackers Can Achieve
| Attack Goal | Example Outcome |
|---|---|
| Disinformation | A medical or financial chatbot confidently states dangerous, false guidance |
| Brand sabotage | A support bot recommends a competitor or disparages its own product |
| Data exfiltration | Injected instructions trick the AI into revealing other users' data |
| Phishing | The AI surfaces attacker-controlled links as "official" resources |
| Bias injection | Hiring or lending assistants is nudged toward discriminatory outputs |
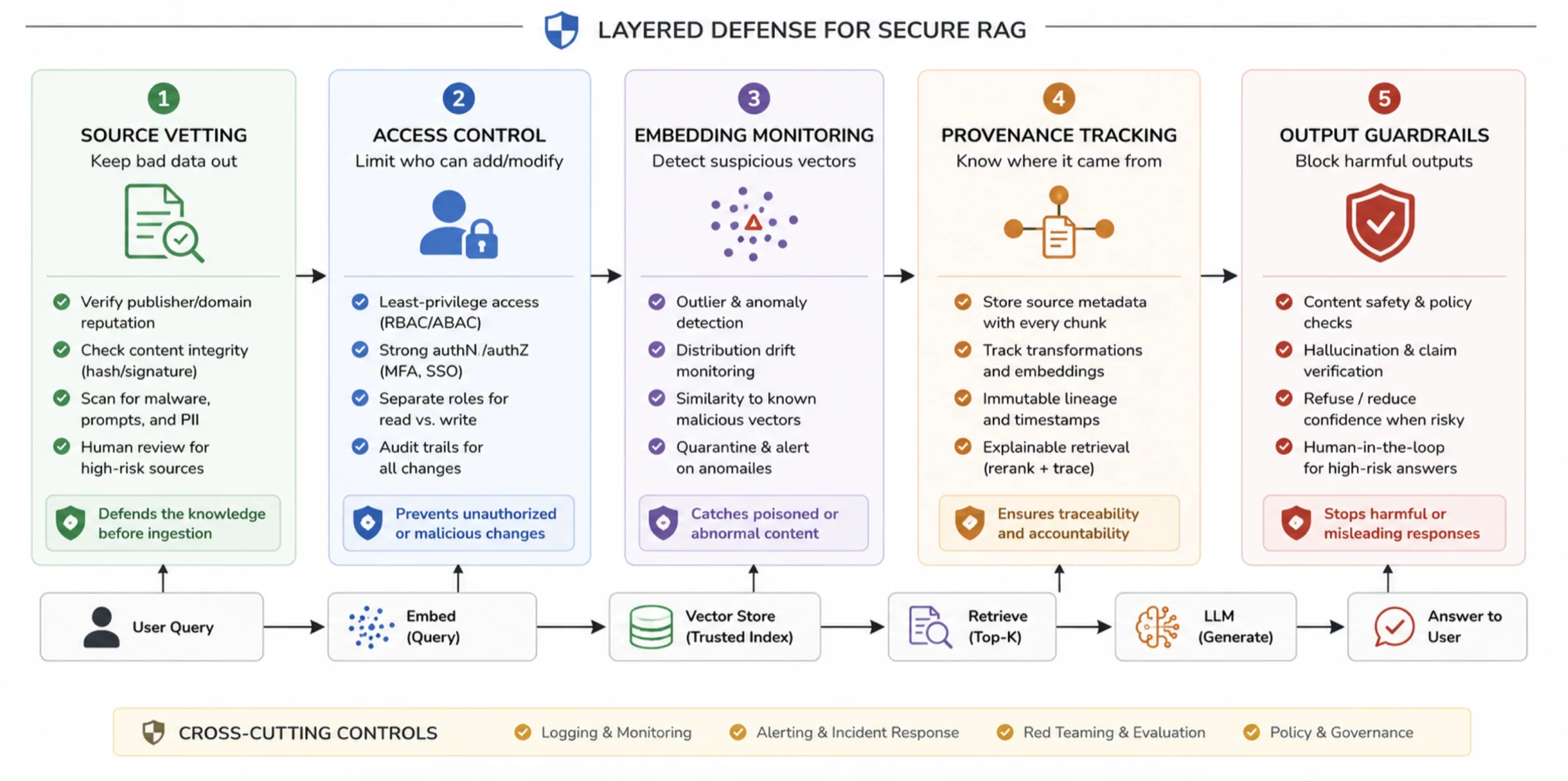
How to Prevent Vector Poisoning
No single control is enough — defense in depth is the rule. These map well onto general web application security practices, applied to the AI pipeline.
1. Vet and Sanitize Ingestion Sources
Treat every data source as untrusted until proven otherwise. Validate, clean, and filter content before it's embedded — strip hidden instructions, scripts, and anomalous formatting. Never auto-ingest from the open web without review.
2. Control Access to the Vector Store
Lock down who and what can write to the database with strong authentication, least-privilege roles, and network isolation. Most poisoning needs a write path — close the easy ones.
3. Validate and Monitor Embeddings
Run anomaly detection on incoming vectors. Poisoned entries often cluster oddly or sit suspiciously close to many unrelated queries. Flag entries that are retrieved far more often than their source justifies.
4. Track Provenance and Enable Rollback
Tag every chunk with its source, author, and ingestion time. If poisoning is discovered, provenance lets you trace and purge every affected entry — and roll the database back to a clean state.
5. Add Output Guardrails and Verification
Put guardrails between retrieval and the user: fact-checking layers, citation verification, and content filters. Require the model to cite sources so suspicious claims can be traced back to their chunk.
6. Audit Retrievals Continuously
Log what gets retrieved for which queries and review it. Combined with real-time AI threat monitoring, continuous auditing turns invisible poisoning into something you can actually catch.
FAQ
What is vector poisoning in simple terms?
Vector poisoning is when an attacker secretly inserts false or malicious information into the database an AI uses to look up answers. Because the AI trusts that database, it then repeats the bad information to users as if it were true — without the model itself ever being hacked.
How is vector poisoning different from data poisoning?
Data poisoning is the broad category of corrupting the data an AI relies on. Vector poisoning is a specific type that targets the vector database used in retrieval-augmented generation (RAG) at inference time — corrupting what the AI retrieves, rather than what it was originally trained on.
Can vector poisoning be detected?
Yes, but it takes deliberate effort. Techniques include anomaly detection on embeddings, monitoring which chunks are retrieved abnormally often, tracking data provenance, and verifying the AI's cited sources. Without these controls, poisoned answers can be mistaken for ordinary hallucinations.
Is vector poisoning the same as prompt injection?
They overlap but aren't identical. Prompt injection hides malicious instructions in input the model reads. Vector poisoning plants malicious content in the retrieval database — which can then deliver a prompt injection at scale to every user who triggers the poisoned chunk. Vector poisoning is often the delivery mechanism for injection.
Who is most at risk from vector poisoning?
Any organization running a RAG system that ingests data from untrusted or semi-trusted sources — public web crawls, user uploads, third-party documents — and especially high-stakes assistants in healthcare, finance, legal, and customer support, where a confident wrong answer causes real harm.
Conclusion
Vector poisoning is a reminder that securing AI means securing its data pipeline, not just its model. By corrupting the vector database at the heart of a RAG system, attackers can make a trusted AI confidently spread false, biased, or harmful information — invisibly and at scale.
The defense is layered: vet your ingestion sources, lock down write access, monitor embeddings and retrievals, track provenance, and add output guardrails. As RAG becomes the default architecture for enterprise AI, treating the vector store as a high-value attack surface isn't optional — it's the cost of deploying AI you can actually trust.