To understand AI inference, think of a student preparing for a final exam. AI Training is the semester spent studying textbooks, attending lectures, and memorizing facts. It is intense, time-consuming, and requires a lot of brainpower.
AI Inference is the exam itself. The student (model) stops learning and starts applying what they know to answer new questions they haven't seen before.
While training happens once, inference happens millions of times. Every time ChatGPT answers a question or FaceID unlocks your phone, that is inference in action. In this guide, we will break down the mechanics, types, and costs of this critical AI phase.
What is AI Inference?
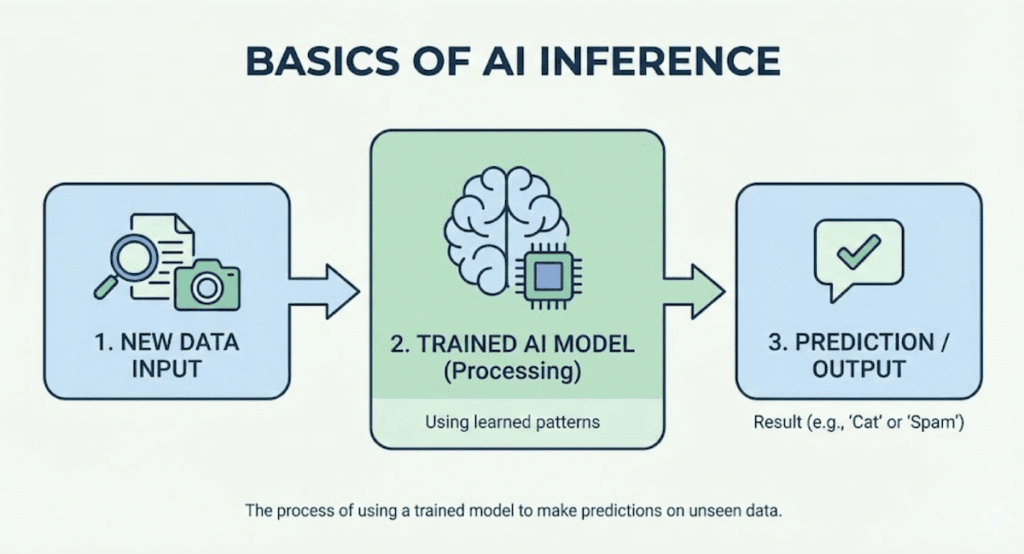
AI inference is the process of using a trained machine learning model to make predictions on new, unseen data. It is the "deployment" phase where the model delivers actual value.
When you feed a photo of a cat into a model, the inference engine processes the pixels through the model's frozen "weights" (learned patterns) and outputs the label "Cat." It doesn't learn from this photo; it just recognizes it based on past training.
AI Inference vs. Training: Understanding the Difference
It is crucial to distinguish between these two phases as they require different hardware and strategies.
Training (The Learning Phase)
- Goal: Create the model.
- Data: Massive datasets (terabytes or petabytes).
- Compute: Heavy, sustained processing (weeks or months).
- Direction: Forward and Backward passes (to correct errors).
Inference (The Action Phase)
- Goal: Use the model.
- Data: Single inputs (one user query or image).
- Compute: Fast, bursty processing (milliseconds).
- Direction: Forward pass only (no learning/backpropagation).
The Inference Process in Machine Learning
How does a model actually make a decision? The process typically follows three steps.
1. Input Processing
Raw data (like a sentence or image) is converted into a format the model understands, usually a list of numbers called a Vector or Tensor. For text, this involves tokenization; for images, it involves resizing and normalizing pixel values.
2. The Forward Pass
The processed data travels through the layers of the neural network. Each layer applies mathematical operations (matrix multiplications) using the model's stored weights, progressively refining the understanding of the input.
3. Output Generation
The final layer produces a probability score. For a chatbot, it predicts the most likely next word; for a fraud detector, it outputs a "Fraud Score" (e.g., 0.95).
Types of Inference: Real-Time vs. Batch
Not all inference happens at the same speed. The choice depends on the urgency of the result.
Real-Time Inference (Online)
This is used when a human is waiting for an answer.
- Examples: Chatbots, Voice Assistants, Fraud Detection at checkout.
- Priority: Low Latency (speed is king).
Batch Inference (Offline)
This is used for processing huge volumes of data where speed matters less than efficiency.
- Examples: Nightly sales forecasting, generating tags for a million-photo library.
- Priority: High Throughput (volume is king).
Where Inference Happens: Cloud vs. Edge AI
Deciding where to run the model is a major architectural decision.
Cloud Inference
Running models in massive data centers (AWS, Google Cloud).
- Pros: Unlimited power, can run giant models like GPT-4.
- Cons: High latency (data travels to server), privacy concerns, internet required.
Edge AI Inference
Running models directly on the device (iPhone, Tesla car, IoT sensor).
- Pros: Instant response, works offline, data stays private.
- Cons: Limited battery and processing power, requires smaller, optimized models.
Optimizing Inference Performance
Running huge models is slow and expensive. Engineers use several techniques to make them faster.
- Quantization: Reducing the precision of the model's numbers (e.g., from 32-bit to 8-bit integers). It makes the model smaller and faster with minimal loss in accuracy.
- Pruning: Removing "dead" neurons or connections that don't contribute much to the output, effectively shrinking the model's brain without making it more dopey.
- Caching: Storing the results of common queries so the model doesn't have to re-compute the answer for the same question twice.
Hardware for AI Inference
Different chips are better suited for different inference tasks.
- CPUs (Central Processing Units): Good for simple, small models or low-volume batch jobs.
- GPUs (Graphics Processing Units): The standard for most AI. Excellent at parallel processing, making them perfect for LLMs and image generation.
- TPUs / NPUs (Tensor/Neural Processing Units): Specialized chips designed only for AI math. They are incredibly efficient for specific high-scale workloads (like Google Search or Apple FaceID).
The Cost of AI Inference
While training costs millions upfront, inference costs accumulate over time. Every time you ask ChatGPT a question, it costs OpenAI a fraction of a cent in electricity and compute.
For businesses, this "variable cost" is dangerous. If a free user generates 1,000 queries a day, the inference bill can quickly exceed the revenue. This economic pressure is driving the race towards smaller, more efficient "Small Language Models" (SLMs) that can run cheaply on cheaper hardware.
Conclusion: The Engine of the AI Economy
Inference is where the rubber meets the road. It is the mechanism that turns static model weights into dynamic business value.
As we move forward, the competitive advantage will shift from "who has the biggest model" to "who can run inference the fastest and cheapest." Understanding this layer of the stack is essential for anyone looking to build sustainable AI products.
Frequently Asked Questions (FAQ)
- Does inference improve the model? Generally, no. Standard inference uses a frozen model. However, user feedback from inference sessions can be saved to retrain the model later.
- Why is inference expensive? It requires keeping massive models loaded in expensive GPU memory (VRAM) 24/7 to ensure instant response times.



