You have probably hit a wall where your application feels slow, hard to scale, and increasingly painful to maintain. CQRS, or Command Query Responsibility Segregation, is one of the most powerful architectural patterns in software development that you can adopt to solve exactly those problems. Once you understand it, you will see it changes how you think about data flow in your entire system.
At its core, CQRS is a simple idea. You split your application's data operations into two distinct paths: commands that change state, and queries that read state. You never let these two paths share the same model.
Understanding the Command Query Responsibility Segregation Pattern
The CQRS pattern traces its roots to the Command-Query Separation principle introduced by Bertrand Meyer. He argued that a method should either change the state of a system or return a result, but never both. CQRS takes this idea and applies it at the architectural level rather than just the method level.
In a traditional application, you likely use one data model for everything. You read from it, write to it, and update it all through the same pipeline. This creates tight coupling, and as your application grows, that coupling turns into a bottleneck.
Any fool can write code that a computer can understand. Good programmers write code that humans can understand. — Martin Fowler
When you apply CQRS, you separate your read model from your write model entirely. Your commands handle all the business logic that changes data. Your queries are optimized purely for fast, efficient data retrieval.
How the Command Side Works in CQRS Architecture
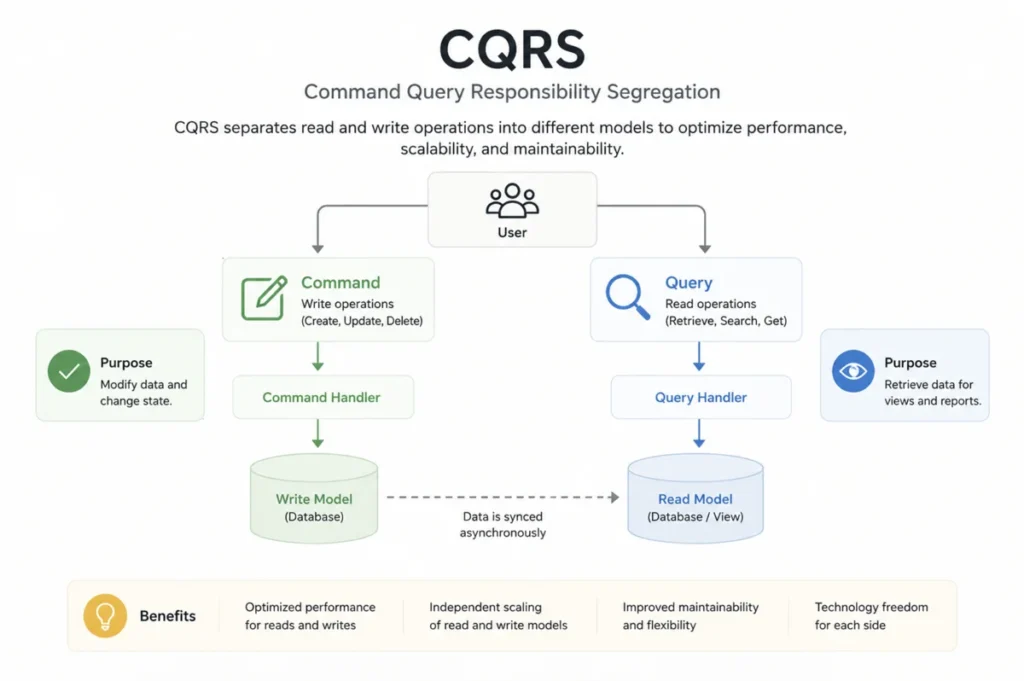
The command side is where your business logic lives. When a user places an order, submits a form, or updates a profile, that action becomes a command. Your command handlers validate the input, apply business rules, and then persist the change to the write store. This is a core responsibility of a principal software engineer designing enterprise systems.
Commands are intentional and descriptive. Instead of a generic update method, you send a command like PlaceOrder or UpdateUserAddress. This makes your system far more expressive and auditable.
- Commands are named after the business action they perform.
- A command handler processes exactly one type of command.
- Commands return no data, only a success or failure signal.
- The write store is optimized for transactional consistency.
- Commands often work naturally alongside Domain-Driven Design (DDD) and benefit from performance-focused design decisions.
How the Query Side Gives You Read Model Flexibility
The query side is where you retrieve and display data. Because it is completely separated from the write side, you can shape your read models to exactly match what your UI or API needs. You are no longer forced to serve your frontend a raw database entity when it only needs three fields.
Your query handlers fetch data from a read store that can be a completely different database, a cache, or a pre-computed view. This separation lets you scale reads independently from writes, which is a massive win for high-traffic applications. Teams using AI and automation to transform backend development find CQRS especially complementary.
You can think of the read model as a set of denormalized, pre-joined views tailored for specific screens or use cases. This makes your queries extremely fast and simple.
CQRS and Event Sourcing: A Natural Partnership
You will often hear CQRS mentioned alongside event sourcing, and for good reason. Event sourcing stores every state change as an immutable event rather than overwriting the current state. This is conceptually similar to how autonomous transactions isolate state changes in database systems. When you combine CQRS with event sourcing, your command side appends events to an event store, and your query side builds read models by replaying those events.
| Aspect | Traditional Architecture | CQRS with Event Sourcing |
|---|---|---|
| Data Model | Single model for reads and writes | Separate read and write models |
| Scaling | Read and write scale together | Reads and writes scale independently |
| Audit Trail | Requires extra logging setup | Built-in via event log |
| Query Performance | Constrained by the write schema | Optimized per query requirement |
| Complexity | Low upfront complexity | Higher upfront, lower long-term |
This combination gives you a full audit history out of the box. If you need a more hands-on look at creating audit log files, that pattern of capturing every change is directly analogous to what event sourcing gives you. You can replay events to rebuild any past state or create a brand new read model without touching your production data.
A Simple CQRS Command Handler Example
Here is what a basic command and its handler might look like in a Node.js-style pseudocode setup. If you are evaluating which coding languages to use for this kind of architecture, JavaScript and TypeScript are solid choices. You can adapt this pattern to any language or framework you use.
// The Command
class PlaceOrderCommand {
constructor(userId, productId, quantity) {
this.userId = userId;
this.productId = productId;
this.quantity = quantity;
}
}
// The Command Handler
class PlaceOrderHandler {
async handle(command) {
const order = Order.create(
command.userId,
command.productId,
command.quantity
);
await this.orderRepository.save(order);
await this.eventBus.publish(new OrderPlacedEvent(order.id));
}
}
Notice that the handler returns nothing to the caller. It validates, persists, and then publishes an event. Your query side will pick up that event and update the read store asynchronously. This asynchronous background processing model is a well-proven approach for decoupling producers from consumers.
When You Should and Should Not Use CQRS
CQRS is not a silver bullet, and you should not apply it everywhere. It adds real complexity to your codebase, especially around eventual consistency between your read and write stores. If your application is simple, a traditional CRUD approach will serve you better. You may also want to explore automatic schema refactoring before committing to a full architectural split.
Premature optimization is the root of all evil. — Donald Knuth
CQRS shines when your read and write workloads have very different characteristics, when you need high scalability, or when your domain logic is complex enough to benefit from the separation. You should consider it seriously if you are building collaborative systems, high-traffic platforms, or anything that requires a rich audit trail.
Signs Your System Is Ready for CQRS
You will start to notice certain pain points that signal your architecture is straining under a unified model. These are the clearest signs that CQRS might be the right move for your team.
- Your database queries are getting complex because your read and write schemas are fighting each other.
- Your application is struggling to scale because reads and writes are coupled to the same bottleneck.
- Your domain model is growing so rich that it is hard to build simple, fast query responses from it.
- You need a detailed audit log or the ability to reconstruct past states of your data.
- Multiple teams are stepping on each other because the data model tries to serve too many masters.
Managing Eventual Consistency in Your CQRS System
One challenge you will need to manage is eventual consistency. When a command is processed, the read model does not update instantly. There is a small delay while your system propagates the change. For most use cases, this is perfectly acceptable, and users rarely notice.
You can design your UI to handle this gracefully. After a command, you can optimistically update the view on the client side while the backend catches up. This gives your users a snappy experience even with asynchronous updates happening under the hood.
Conclusion
CQRS and Command Query Responsibility Segregation give you a powerful tool for building scalable, maintainable, and expressive software systems. By separating how you write and read data, you unlock the freedom to optimize each side independently. You make your domain logic clearer, your queries faster, and your architecture much easier to evolve.
You do not need to adopt CQRS all at once. You can apply it incrementally to the parts of your system where it delivers the most value. This kind of incremental approach is also central to modernizing legacy code without rewriting everything at once. Start with one bounded context, learn the pattern deeply, and expand from there as your confidence and your system's needs grow.



