Large Language Models (LLMs) like GPT-5 and Claude 4 have revolutionized natural language processing, but they suffer from a persistent and dangerous flaw: hallucination. In the context of AI, a hallucination occurs when a model generates a response that is grammatically correct and logically plausible but factually entirely invented.
Unlike a database that returns an error when data is missing, an LLM will often fabricate names, dates, and citations with absolute confidence. For enterprises deploying AI, this "confident liar" behavior is a critical risk vector.
In this article, we will explore the root causes of AI hallucinations, from the probabilistic nature of next-token prediction to the artifacts of reinforcement learning.
What are Hallucinations in LLMs?
Hallucination in large language models is not a "bug" in the traditional sense; it is a feature of how they generate text. These models are not knowledge bases; they are compression engines that reconstruct information based on statistical likelihood.
When a model "hallucinates," it is essentially predicting a sequence of words that looks like a valid answer based on the patterns it learned during training, even if the semantic content is detached from reality. This often manifests as "source conflation," where the model merges two unrelated factual events into a single, convincing narrative.
The Probabilistic Nature of LLMs
To understand why LLMs hallucinate, we must look at their core architecture. LLMs are probabilistic engines designed to predict the next token (word fragment) in a sequence.
The "Stochastic Parrot"
When you ask a question, the model does not "think" or "look up" facts. It calculates the probability distribution of every possible next word.
- If the model is 99% sure the next word is "Paris" (e.g., "The capital of France is..."), it outputs a fact.
- If the model is uncertain (e.g., "The capital of Atlantis is..."), it still must pick a word. It chooses the most statistically plausible candidate, effectively inventing a fact to satisfy the pattern.
This probabilistic nature of LLMs means they prioritize fluency and coherence over factual accuracy. They are optimized to sound human, not to be truthful.
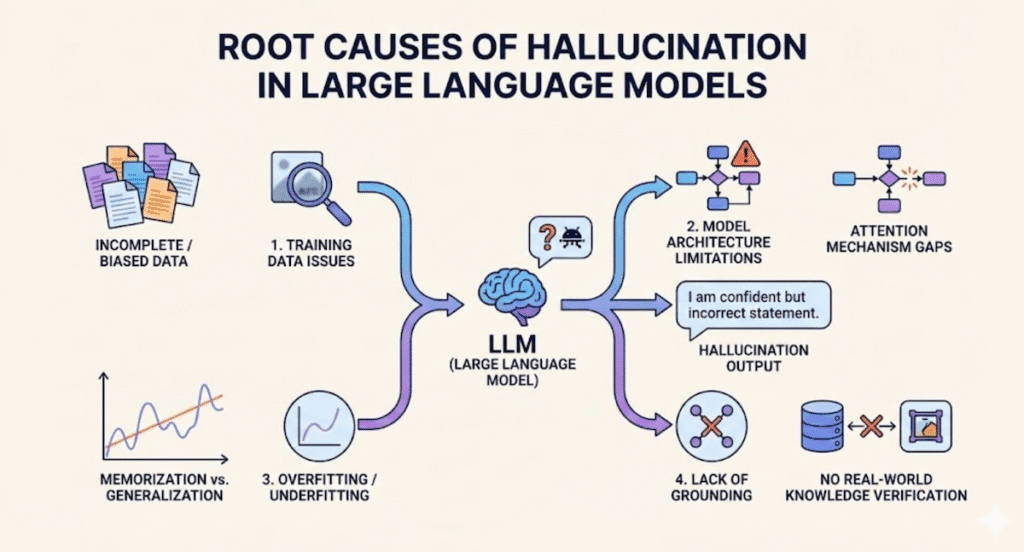
Training Data Issues: The Source of the Noise
The old adage "Garbage In, Garbage Out" applies heavily to Generative AI. LLM training data issues are a primary driver of hallucinations.
Data Quality and Bias
Models are trained on vast scrapes of the open internet (Common Crawl), which contains misinformation, satire, fiction, and conspiracy theories. If a model reads 1,000 articles stating the earth is flat and 1,000 stating it is round, it may treat both as equally valid statistical patterns.
The Knowledge Cutoff Problem
Models have a fixed training cutoff. If you ask about an event that happened yesterday, the model has zero data on it. Instead of saying "I don't know," it may try to extrapolate from older data, leading to hallucinations about recent events that never occurred.
Lack of Grounding and Real-World Understanding
A fundamental cause of error is the lack of grounding in AI. "Grounding" refers to the model's ability to link a word (symbol) to its real-world meaning (referent).
To an LLM, the word "apple" is just a vector of numbers that often appears near "red," "fruit," and "pie." The model has no sensory experience of an apple. Because it manipulates symbols without understanding their physical reality, it can easily generate sentences that are grammatically perfect but physically impossible (e.g., "The apple melted in the sun").
Source Conflation and Compression
LLMs are essentially lossy compression algorithms for the internet. They compress terabytes of text into gigabytes of parameters.
Lossy Compression
During this compression, specific details are lost. Source conflation in LLMs occurs when the model remembers the vibe of a story but forgets the specific actors. It might attribute a quote by Albert Einstein to Benjamin Franklin because both are "wise historical figures" embedded in similar vector spaces.
It generates a "remix" of facts rather than a retrieval of facts, leading to subtle but dangerous errors.
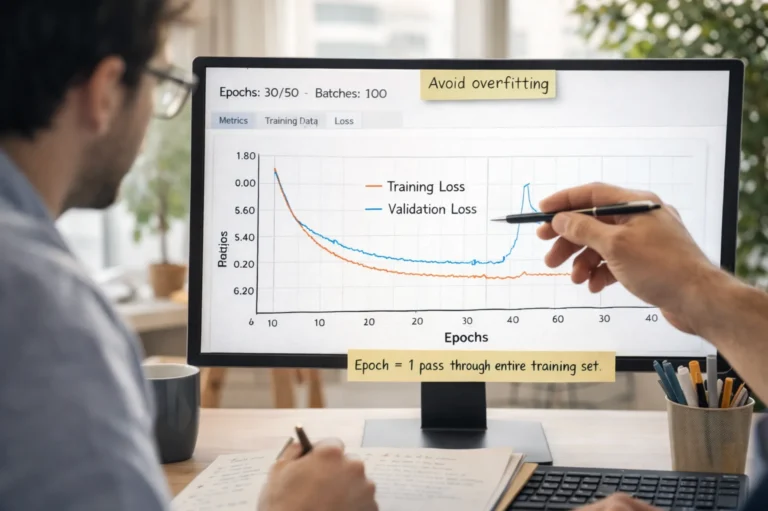
The Impact of Overfitting and Underfitting
Finding the balance in model training is notoriously difficult.
- Overfitting: If a model memorizes its training data too closely, it cannot generalize. When faced with a novel prompt, it may regurgitate memorized (and potentially irrelevant) text verbatim.
- Underfitting: If a model is too loose, it fails to capture the relationships between facts. This leads to overfitting and hallucinations where the model makes broad, sweeping generalizations that are factually incorrect.
The Role of RLHF (Reinforcement Learning from Human Feedback)
Ironically, the process used to make models "safer" can also make them hallucinate. In RLHF, human raters grade model responses.
If humans consistently rate "confident" answers higher than "I don't know" answers, the model learns sycophancy—telling the user what they want to hear. The model learns that making up a plausible answer yields a higher reward than admitting ignorance, effectively incentivizing hallucination.
Strategies for Preventing LLM Hallucinations
While we cannot eliminate hallucinations entirely, we can mitigate them.
- Retrieval-Augmented Generation (RAG): Instead of relying on the model's internal memory, preventing LLM hallucinations often involves forcing the model to look up answers in a trusted external database before responding.
- Prompt Engineering: Asking the model to "cite its sources" or "think step-by-step" (Chain of Thought) can reduce errors by forcing the model to generate a logical path before the final answer.
- Temperature Control: Lowering the "temperature" setting (randomness) of the model forces it to choose only the most probable tokens, reducing "creative" errors.
Conclusion: Managing the Risk
Hallucinations are an intrinsic part of how Generative AI works today. They are the cost of having a system that can be creative and conversational.
For developers and businesses, the key is not to wait for a "perfect" model, but to build architecture (like RAG) that verifies AI output. We must move from trusting the model to auditing the model.
Frequently Asked Questions (FAQ)
- Can hallucinations be fixed by adding more data? Not necessarily. More data can sometimes add more noise. Better curation of data is usually more effective than just more data.
- Do larger models hallucinate less? Generally, yes. Larger models (like GPT-4) have better reasoning capabilities and larger memory capacities, reducing the rate of source conflation compared to smaller models.